0 性能优化的基本问题
基本原则
- No profiled, Never optimize (只有能被度量的问题才能得到最终解决)
基本认知
系统和程序的瓶颈点会不断转移
当我们消除当前的瓶颈点后,之前不是瓶颈的点就会变成新的瓶颈点

几乎不存在任何场景下都百分之百正向的优化
大多数情况下,我们做的优化都会有一些 Bad Case 或者是使用了更多系统资源。所以我们在完成一个性能优化后, 一定要思考清楚这个优化的Bad Case 是什么,充分进行性能测试。 比如:
- 常见的 Local Cache 优化: 当 Local Disk 本身的 IO 压力很大时,可能就没有直接读取 Remote Storage 快
- 谓词下推优化: 下推太多的谓词可能导致重复过滤,浪费更多的 CPU
- Perfetch 优化:高并发时可能会有 Bad Case
- IO 合并优化: 有时候虽然减少了 IO 读取次数,但是却导致读取了更多的数据
典型,全面,真实的性能测试集是打造一款通用高性能数据库的基础
在 StarRocks 多年的性能优化的过程中,出现过几次,我们预期理论上会有优化,但是标准测试集优化效果不明显,于是暂时搁置了这个优化,最后在用户的真实生产环境中又发现很有效的 Case。这对我们的启发是:
- 在一款数据库性能优化的过程中,我们要有目的,有计划的持续打造我们的性能测试集,在用户实际生产环境中,每遇到一类我们之前没有 Cover 的 Case,都应该及时加入到我们的性能测试集中。 这样的好处是每当我们实现一个新的优化点,都可以有足够多典型的测试用例,可以促使我们考虑的优化点更加全面,也可以防止我们的性能回退。
- 几乎所有静态的配置必然会在用户生产环境中遇到 Bad Case,所以自适应的优化策略不可避免。
查询性能优化的意义
对一个数据库产品来说:
- 性能提升 10 倍: 用户的机器资源可以从100台减少到10台
- 从 10 秒 到1秒: 交互式分析体验, 让之前不可能上线的应用变得可能
- 支撑更高查询并发
- 敲门砖: 产品 POC 几乎不会缺少的环节,因为查询性能相对比较容易量化
- 无需复杂预处理: 从大宽表变成灵活的现场多表 Join, 降低数据加工的成本
- 从 ETL 变成 ELT: 让 ELT 更容易实现
对一个数据库工程师来说:
- 当一个优化有好几倍甚至是数量级的提升时,会有很大的成就感
- 专业能力的快速提升,因为数据库的性能优化是一个多维度,很复杂的系统工程,从架构到细节,从硬件到软件,从内核到应用,几乎都会有涉及
查询性能优化的目标
database performance can be defined as the optimization of resource use to increase throughput and minimize contention, enabling the largest possible workload to be processed.
从应用视角,主要是 Latency 和 Throughput。 (在总资源不变的情况下 缩短响应时间,一般都可以提升吞吐率。)
从系统资源的视角,我们要优化 CPU, IO, Memory, NetWork 等系统资源的利用率。 (在性能优化的过程中,我们在关注查询吞吐和时延的同时,也一定要关注系统资源的利用率。因为有时候的性能提升几倍的同时,也多用了几倍的 CPU)
CPU 架构下的数据库性能优化有尽头吗?
答案是 性能优化永无止境 ,因为
- 硬件在持续变化:底层硬件的变动可能直接导致上层软件的架构革新或者是数据结构和算法层面的革新
- 数据库架构在持续变化:架构的变化会可能导致我们的执行策略,执行模型,优化重点都发生变化
- 更多的上下文,更多的优化策略:只要有更多的上下文,更多的信息,我们就可以实现针对性的优化
- 数据结构和算法层面的创新:数据结构和算法层面的创新是永远不会停止的,一个简单的 Hash 表 工业界都从来没有停止优化
- 执行策略层面的创新:比如 CTE 复用,聚合下推,各类 Runtime Filter
- From Manually To Adaptive:在未来,我们必然会向用户屏蔽掉各种配置,各种 Session 变量,而每去掉一个配置,就可能意味着我们会多一种自适应执行的策略
生产环境的性能 VS Benchmark 的性能
很多时候,我们的性能测试都是在标准环境进行,都尽可能屏蔽噪音,但是在生产环境,要想取得在 Benchmark 中的性能数据,我们可能还要再付出10倍不止的精力:
- 大查询影响小查询
- 导入,查询,Compaction,统计信息等任务相互影响
- 并发控制 & 查询排队
- 查询超时 & Retry
- PT99, Not Avg
- 慢节点
- 数据倾斜
在生产环境中,上面的每一个问题都不是很好解决,都是一个大型的优化项目。
性能优化的权衡
在考虑要不要进行一个性能优化时,我们还需要从下面几点进行权衡:
- 代码复杂度
- 兼容性
- 稳定性
- 优化的投入产出比
- 优化的通用性
- 性能的可预测性
我们永远都要有这样一个意识:
- 不是所有的需求都要满足
- 不是所有的Bug都要修复
- 不是所有的优化都要实现
OLAP 数据库性能优化的未来
1 Serverless 架构下面向成本的性能优化:
参考 如何打造一款极速分析型数据库:ServerLess 之极致弹性 要想在 Serverless 架构下取得很好的性能,我们的整个架构,执行框架,算法实现上就不能单点和串行,必须保证每个SQL 都可以随着节点数增多性能可以获得成比例提升,其次,我们也必须解决数据倾斜问题,否则,就无法充分利用整个集群的资源。
2 真实业务场景的自适应执行优化:
基于不同的数据分布,数据技术,数据基数,数据相关性,优化器很难保证任何时候都产生比较好的plan,所以自适应执行的优化不可避免,可以参考 数据库之美 —— 查询自适应执行
3 真实历史数据的 AI 优化
- 在批处理场景下,我们可以基于历史运行任务的信息去进行 History Base 的优化
- 我们可以根据用户真实执行SQL的各种指标数据,结合机器学习,进行自动推荐物化视图,自动 clusting,优化执行计划等等
4 Fuse Vectorized And Compilation
Vectorized 和 Compilation 并不冲突, 我们可以在 Compilation 的时候生成向量化的代码
在 Vectorized 引擎里面,下面这些场景,可以考虑用 Compilation 加速:
- Complex Expression
- UDF, UDAF, UDTF
- 多列 Sort, Aggregate
- GPU
5 用 GPU, FPGA 等硬件加速计算
6 利用机器学习和统计学习自动创建 MV,索引,调整数据分布
如何成长为数据库性能优化专家
- CPU & 内存 & 网络 & IO 的专业知识 (原理,性能指标,性能工具)
- 数据库领域的专业知识
- 性能测试的工具和方法论
- 数据库领域各种优化思路,
- 关注学术和工业界的进展
- 关注新硬件,新架构
- 目标系统原理,源码的深刻理解和掌握
性能优化是一门工程,实践出真知,大家还是多动手,多尝试,多积累经验。
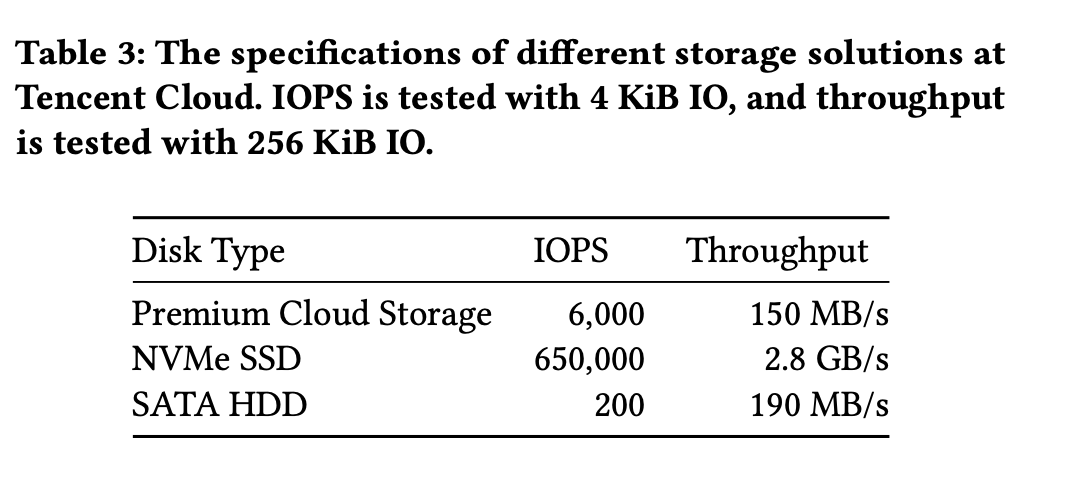
关键性能数据
不同介质的访问延迟数据
0.5 ns - CPU L1 dCACHE reference
1 ns - speed-of-light (a photon) travel a 1 ft (30.5cm) distance
5 ns - CPU L1 iCACHE Branch mispredict
7 ns - CPU L2 CACHE reference
71 ns - CPU cross-QPI/NUMA best case on XEON E5-46*
100 ns - MUTEX lock/unlock
100 ns - own DDR MEMORY reference
135 ns - CPU cross-QPI/NUMA best case on XEON E7-*
202 ns - CPU cross-QPI/NUMA worst case on XEON E7-*
325 ns - CPU cross-QPI/NUMA worst case on XEON E5-46*
10,000 ns - Compress 1K bytes with Zippy PROCESS
20,000 ns - Send 2K bytes over 1 Gbps NETWORK
250,000 ns - Read 1 MB sequentially from MEMORY
500,000 ns - Round trip within a same DataCenter
10,000,000 ns - DISK seek
10,000,000 ns - Read 1 MB sequentially from NETWORK
30,000,000 ns - Read 1 MB sequentially from DISK
150,000,000 ns - Send a NETWORK packet CA -> Netherlands
| | | |
| | | ns|
| | us|
| ms|
执行典型指令 1/1,000,000,000 秒 =1 纳秒
从一级缓存中读取数据 0.5 纳秒
分支预测错误 5 纳秒
从二级缓存中读取数据 7 纳秒
互斥锁定 / 解锁 25 纳秒
从主存储器中读取数据 100 纳秒
在 1Gbps 的网络中发送 2KB 数据 20,000 纳秒
从内存中读取 1MB 数据 250,000 纳秒
从新的磁盘位置读取数据 ( 寻轨 ) 8,000,000 纳秒
从磁盘中读取 1MB 数据 20,000,000 纳秒
在美国向欧洲发包并返回 150 毫秒 =150,000,000 纳秒
https://colin-scott.github.io/personal_website/research/interactive_latency.html

内存带宽
RAM bandwidth could be 50 GB/sec
SSD 带宽
SSD could be only 600 MB/sec.
性能的可预测性
性能指标的测量
性能优化相关的理论
Amdahl's Law 阿姆达尔定律
Little‘s Law
稳定的系统中同时被服务的用户数量等于用户到达系统的速度乘以每个用户在系统中驻留的时间,适用于所有需要排队的场景。
系统中物体的平均数量( L )等于物体离开系统的平均速率( v )和每个物体在系统中停留的平均时间( W)的乘积。
并发数=吞吐量 * 响应时间 = QPS * 查询时延
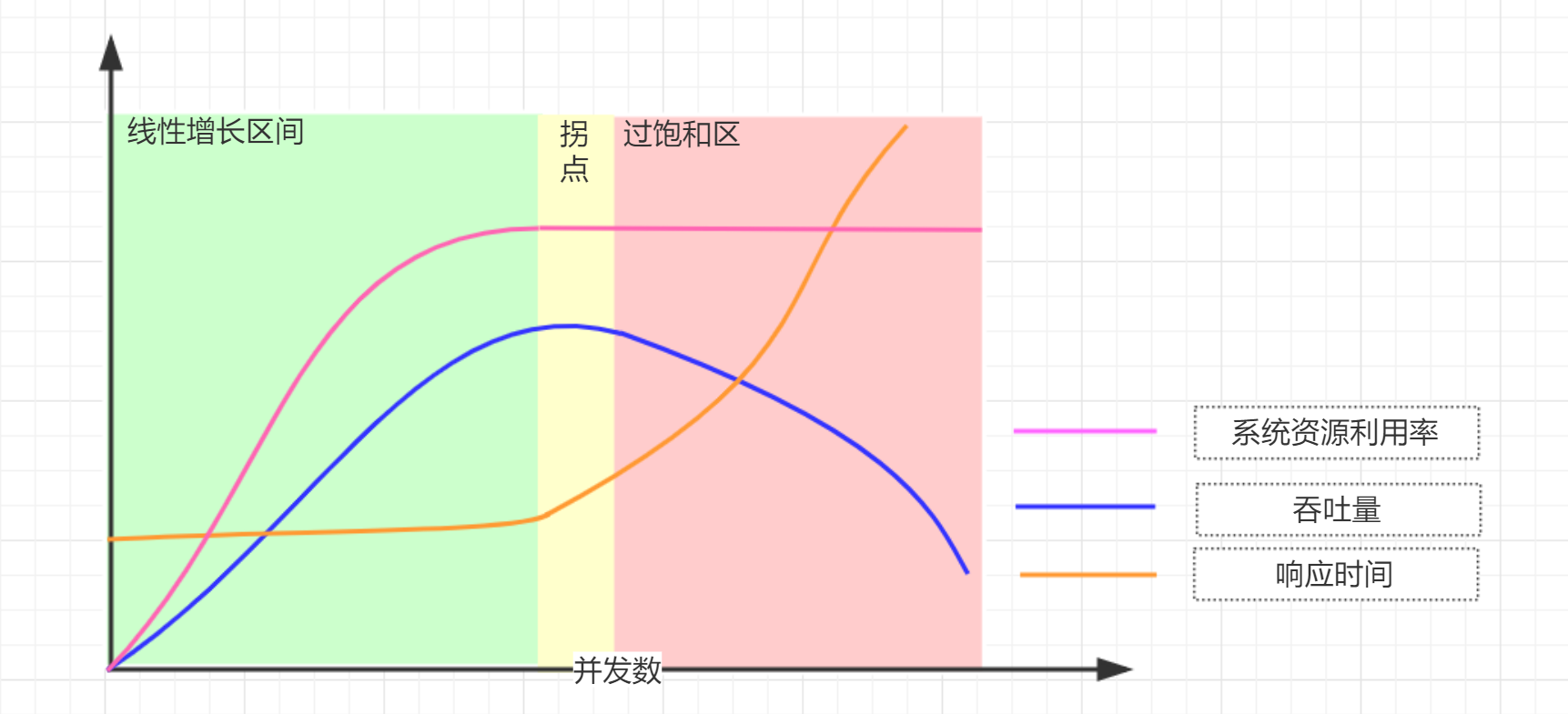
从上图这个曲线可以看到:在系统资源没有到瓶颈之前:请求并发数越高,系统资源利用率越高,吞吐量越高,响应时间基本不变,但是当某个系统资源达到瓶颈时,吞吐量会明显下降,响应时间明显增大。