查询执行器
查询执行器单核想要实现极致的查询性能,需要满足两点:
1 处理的数据尽可能少且尽可能快;
2 网络传输的数据尽可能少且尽可能快。
查询执行器处理数据量的多和少完全由查询优化器决定,查询执行器本身几乎无法决定;查询执行器处理数据如何尽可能快,就是向量化执行器的执行,我们在下一小节单独讲。 网络传输时数据如何尽可能少,尽可能快,如下图所示:
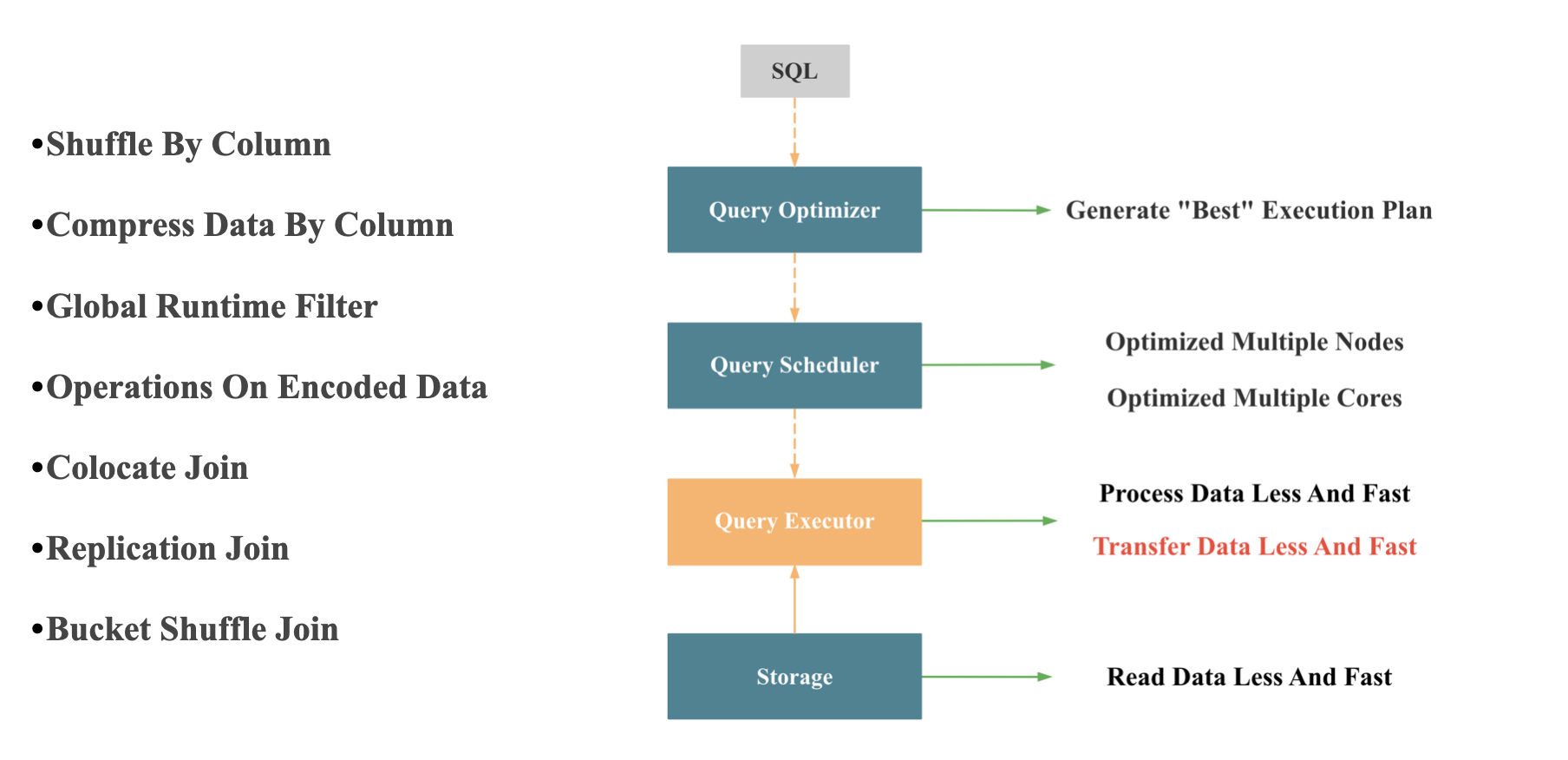
- 按列 Shuffle: 向量化引擎中按列处理更加高效
- 按列 压缩
- Join 分布式执行时尽可能避免网络传输:主要由查询优化器和查询调度器合作完成
- Global Runtime Filter: StarRocks 实现的 Global Runtime Filter 在如何减少网络传输上做了很多优化,这个功能之后我司会安排专门的分享介绍
- Operations On Encoded Data: 主要是针对有字典编码的低基数字符串进行的优化,StarRocks的创新之处在于,在支持数据自动 Balance 的分布式架构下,实现了全局字典的维护,并结合 CBO 优化器,对包含低基数字符串的查询进行了全面加速,这个大功能之后我司也会安排专门的分享介绍。 这里我简单介绍下,对低基数字符串查询全面加速的原理:

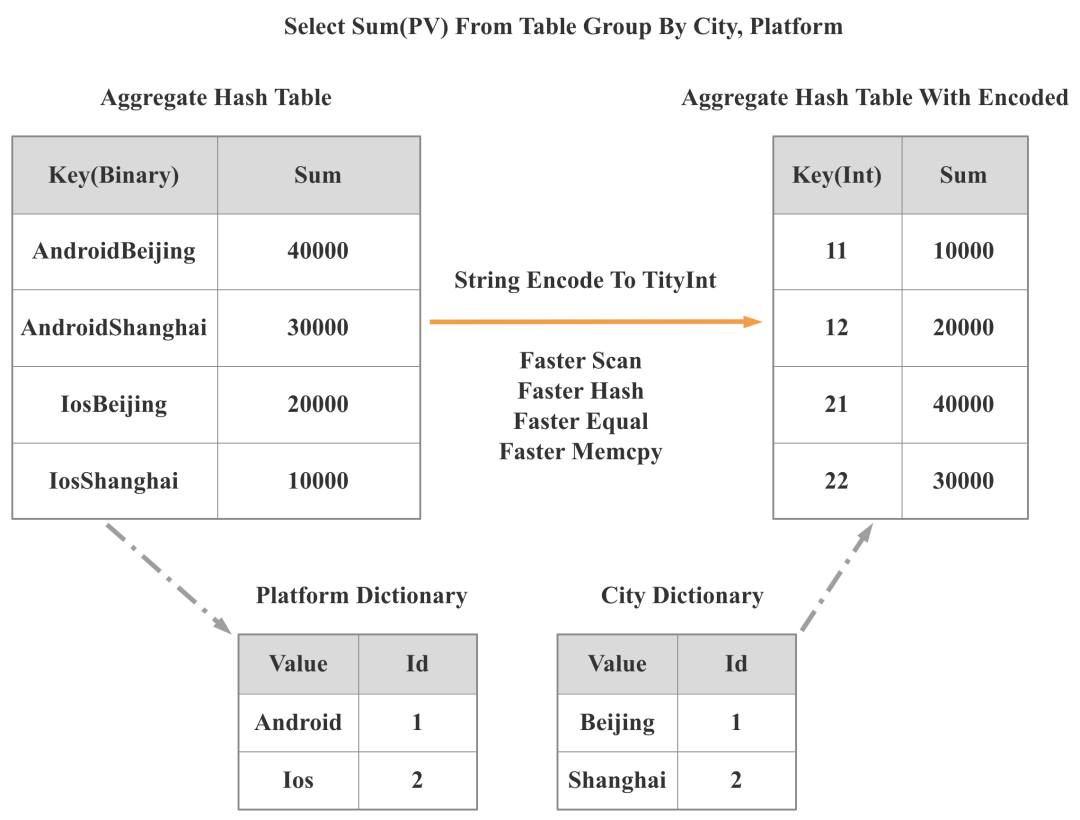
如上图所示,对于SQL Group By City, Platform, 如果 City, Platform 都是低基数字符串,我们就可以将对两个字符串列的 Hash 聚合变为针对两个 Int 列的 Hash 聚合,这样在 Scan, Shuffle,Hash,Equal,Memcpy 等多个重要操作上都会变快很多,我们实测整体查询性能可以有 3 倍的提升。
数据库的几种常见执行模式
- Iterator Model: Tuple-at-a-time
- Materialization Model: Operator-at-a-time
- Vectorized / Batch Model: Vector-at-a-time
Iterator Model 的优缺点
优点:
- 实现简单
- 内存占用小
缺点:
- CPU 利用效率太低,CPU的大部分处理时不是用来真正的处理数据,而是在遍历查询操作树。
最理想的执行模型
- 充分利用多核能力同时处理一个查询
- 每个线程执行查询编译后的 Plan
- 查询编译的 Plan 触发向量化操作
Push VS Pull
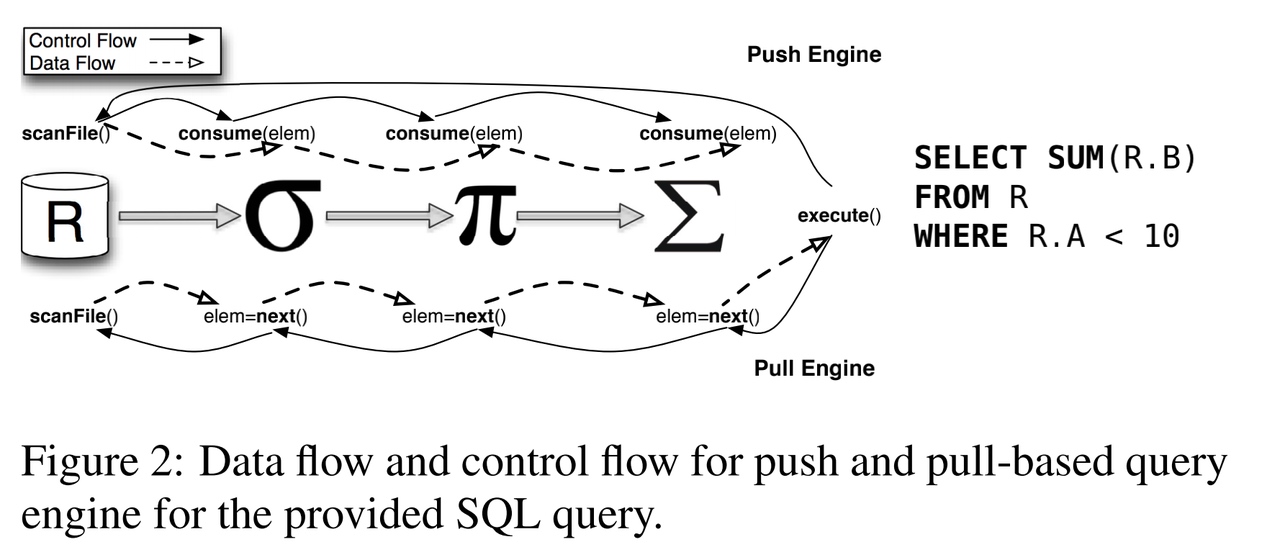
Pull 执行方式是 Top-to-Bottom,从 root 节点开始,从孩子节点 "pull" 数据 Push 执行方式是 Bottom-to-Top,从 left 节点开始,"push" 数据到父节点
如上图所示,在Push的执行方式中,数据流和控制流方向一致,在Pull的执行方式,数据流和控制流方向相反。
大家可以从下面这段伪代码中更直接地体会Push和Pull的区别:
// pull: 先从相邻前驱的 Operater(调用getChild)获得Chunk,
// 然后调用具体算子的process函数处理,最后返回算出的Chunk
class PhysicalOperator {
public:
Chunk getChunk() {
auto input_chunk = getChild().getChunk();
auto result_chunk = process(input_chunk);
return result_chunk;
}
virtual Chunk process(Chunk const& src) = 0;
}
// push:src_chunk由相邻前驱算子传入, 调用具体算子的process函数处理, 得到结果之后,
// 通过相邻后继算子(getNextOperator获得)的consume函数,交给下一级算子处理.
class PhysicalOperator {
public:
void consume(Chunk const& src_chunk) {
auto result_chunk = process(src_chunk);
getNextOperator().consume(result_chunk);
}
virtual Chunk process(Chunk const& src) = 0;
}
总的来说,Push 模型能做到的事情,Pull 模型也能做到
Push 模型中,Producers 驱动整个流程;Pull 模型中,Consumers 驱动整个流程。
Push 模型的优点
- 数据流和控制流解耦,每个算子自身不用处理控制逻辑
- 高效的支持 DAG 的plan,不只是 Tree 的plan, 支持多路输出,可以进行CTE 复用优化 和 Scan Share 优化
- 可以方便地进行 yield
- 对异步IO 更友好,处理 IO 任务时,将对应算子暂停,数据就绪是唤醒对应的算子
- 对 Code-gen 模型更友好
- Better code and data locality:Data is not pulled by operators but pushed towards the operators.
Push 模型的缺点
- 不好处理 Sort-Merge join
- 不好处理 Limit 短路
- 不好处理 Runtime Filter
向量化执行器
What is Vectorized Query Engine
向量化执行的核心是批量按列进行处理。

- Data Use Column Layout All Time: Disk, Memory, NetWork
- Data should be processed by batch way (4096 rows)
- Data should be computed by column formant, not row formant
- Should use SIMD Instructions as much as possible
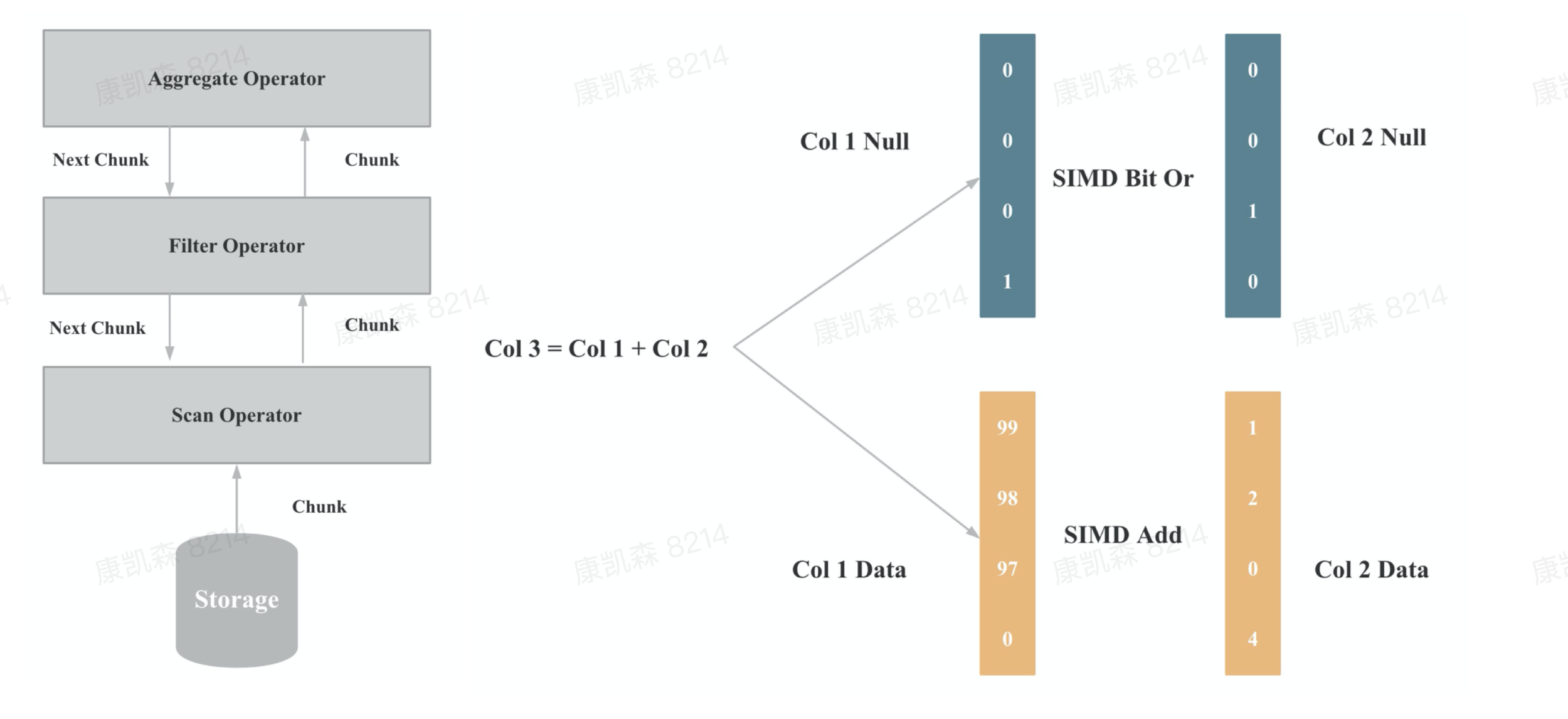
向量化在实现上主要是算子和表达式的向量化,上图一是算子向量化的示例,上图二是表达式向量化的示例,算子和表达式向量化执行的核心是批量按列执行,批量执行,相比与单行执行,可以有更少的虚函数调用,更少的分支判断;按列执行,相比于按行执行,对 CPU Cache 更友好,更易于SIMD优化。

如上图所示,向量化执行工程的挑战包括:
- 磁盘,内存,网络的数据都按照列式布局
- 所有的算子都必须向量化
- 所有的表达式都必须向量化
- 尽可能使用 SIMD 指令
- 尽可能优化 CPU Cache
- 重新设计内存管理机制
- 重新设计重要算子的算法和数据结构
- 整体性能要提升5倍,意味着所有算子和表达式性能都必须提升 5 倍,任何一个算子和表达式慢了,整体性能就无法提升5倍。
向量化执行的架构没有任何难点,难点是工程实现,难点是实现细节。 向量化执行的目的就是优化性能,所以整个向量化执行其实是一个巨大的性能优化工程。

如上图所示,StarRocks 向量化执行性能优化的手段主要包括以上7种,其中 2 - 7 任何一个环节处理不好,都无法实现一个高性能的向量化执行引擎。
向量化为什么可以提升数据库性能?
本文所讨论的数据库都是基于 CPU 架构的,数据库向量化一般指的都是基于 CPU 的向量化,因此数据库性能优化的本质在于:一个基于 CPU 的程序如何进行性能优化。这引出了两个关键问题:
- 如何衡量 CPU 性能
- 哪些因素会影响 CPU 性能
第一个问题的答案可以用以下公式总结:CPU Time = Instruction Number CPI Clock Cycle Time
Instruction Number 表示指令数。当你写一个 CPU 程序,最终执行时都会变成 CPU 指令,指令条数一般取决于程序复杂度。 CPI 是 (Cycle Per Instruction)的缩写,指执行一个指令需要的周期。 Clock Cycle Time 指一个 CPU 周期需要的时间,是和 CPU 硬件特性强关联的。
我们在软件层面可以改变的是前两项:Instruction Number 和 CPI。那么问题来了,具体到一个 CPU 程序,到底哪些因素会影响 Instruction Number 和 CPI 呢?
我们知道 CPU 的指令执行分为如下 5 步:
- 取指令
- 指令译码
- 执行指令
- 内存访问
- 结果写回寄存器
其中 CPU 的 Frontend 负责前两部分,Backend 负责后面三部分。基于此,Intel 提出了 《Top-down Microarchitecture Analysis Method》的 CPU 微架构性能分析方法,如下图所示:
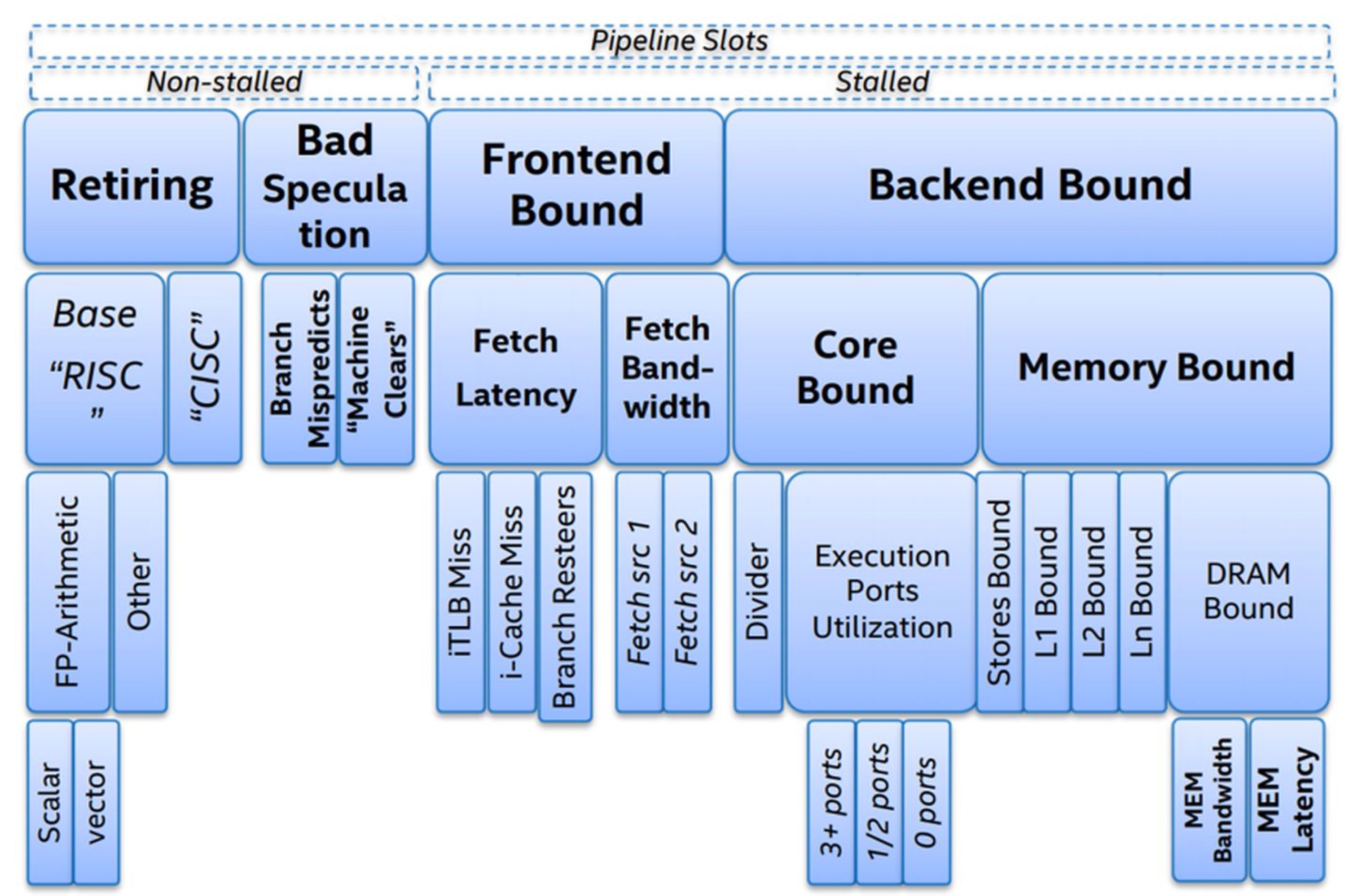
Top-down Microarchitecture Analysis Method 的具体内容大家可以参考相关的论文,本文不做展开,为了便于大家理解,我们可以将上图简化为下图(不完全准确):
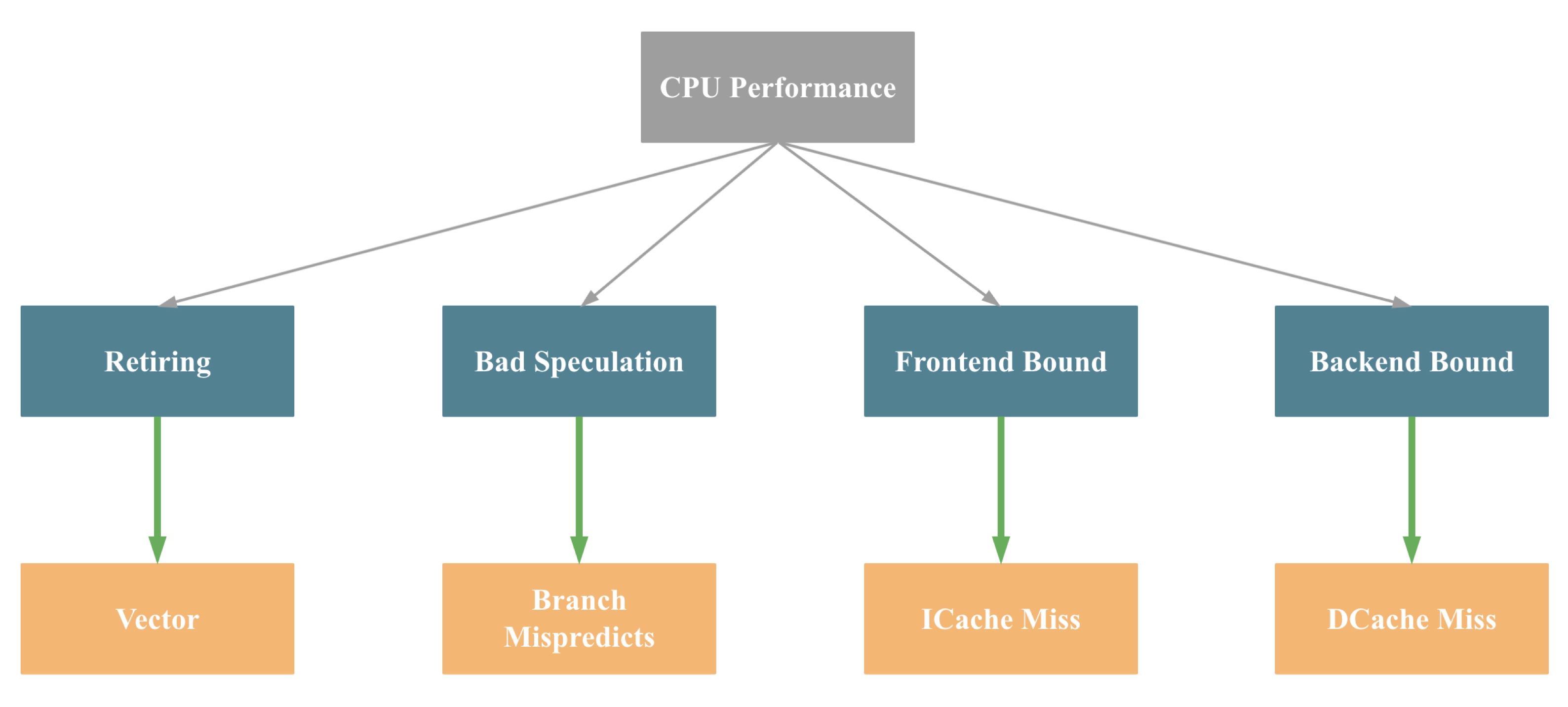
即影响一个 CPU 程序的性能瓶颈主要有4大点:Retiring、Bad Speculation、Frontend Bound 和 Backend Bound,4个瓶颈点导致的主要原因(不完全准确)依次是:缺乏 SIMD 指令优化,分支预测错误,指令 Cache Miss, 数据 Cache Miss。
再对应到之前的 CPU 时间计算公式,我们就可以得出如下结论:
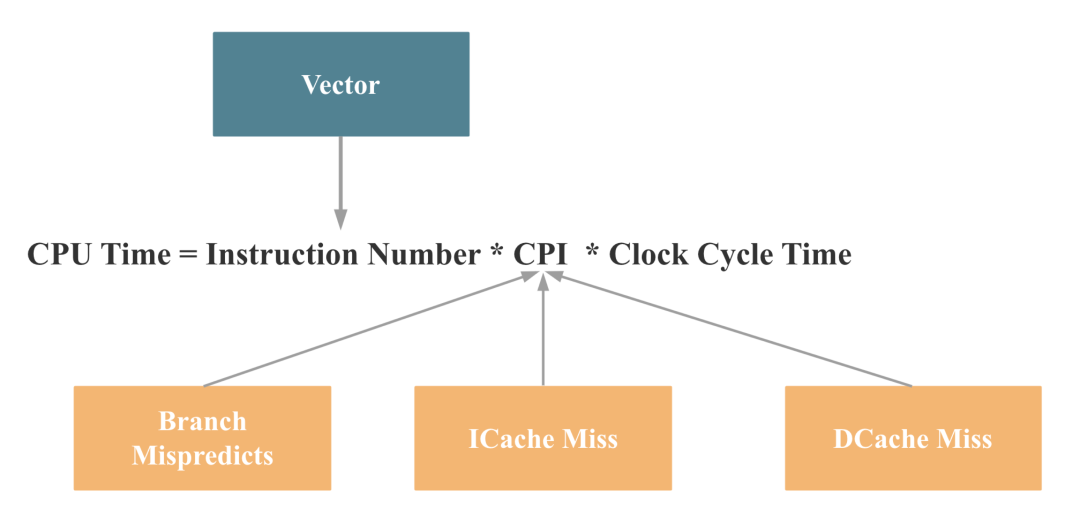
而数据库向量化对以上 4 点都会有提升。 主要原因如下,相比于传统的按行解释执行,向量化执行有以下优点:
- Interpretation 执行的开销更低(批量执行的优点),更少的虚函数调用,更少的分支预测失败
- 对 SIMD 执行更加优化 (按列执行的优点)
- 对 CPU Cache 更加优化 (经常操作顺序的内存)
- 延迟物化:只需要在最后必要的时候将最终需要的列拼成行
算子和表达式向量化的关键点
数据库的向量化在工程上主要体现在算子和表达式的向量化,而算子和表达式的向量化的关键点就一句话:Batch Compute By Column, 如下图所示:
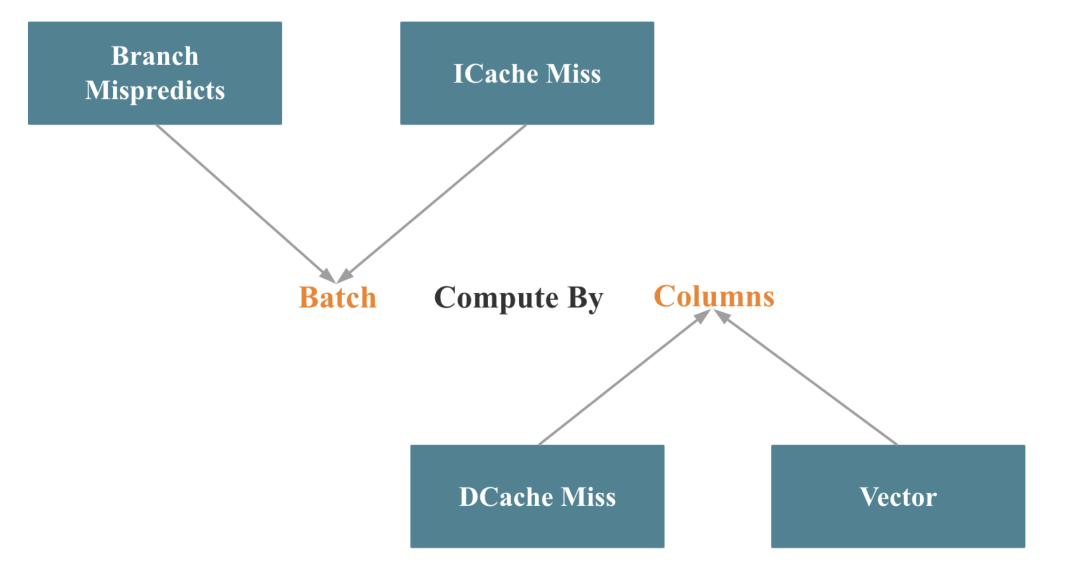
对应 Intel 的 Top-down 分析方法,Batch 优化了 分支预测错误和指令 Cache Miss,By Column 优化了 数据 Cache Miss,并更容易触发 SIMD 指令优化。
Batch 这一点其实比较好做到,难点是对一些重要算子,比如 Join、Aggregate、Sort、Shuffle 等,如何做到按列处理,更难的是在按列处理的同时,如何尽可能触发 SIMD 指令的优化。
数据库向量化如何进行性能优化
前面提到,数据库向量化是一个巨大的、系统的性能优化工程,两年来,我们实现了数百个大大小小的优化点。我将 StarRocks 向量化两年多的性能优化经验总结为 7 个方面 (注意,由于向量化执行是单线程执行策略,所以下面的性能优化经验不涉及并发相关):
高性能第三方库:在一些局部或者细节的地方,已经存在大量性能出色的开源库,这时候,我们可能没必要从头实现一些算法或者数据结构,使用高性能第三方库可以加速我们整个项目的进度。在 StarRcoks 中,我们使用了 Parallel Hashmap、Fmt、SIMD Json 和 Hyper Scan 等优秀的第三方库。
数据结构和算法:高效的数据结构和算法可以直接在数量级上减少 CPU 指令数。在 StarRocks 2.0 中,我们引入了低基数全局字典,可以通过全局字典将字符串的相关操作转变成整形的相关操作。如下图所示,StarRcoks 将之前基于两个字符串的 Group By 变成了基于一个整形的 Group By,这样 Scan、Hash 计算、Equal、Memcpy 等操作都会有数倍的性能提升,整个查询最终会有 3 倍的性能提升。
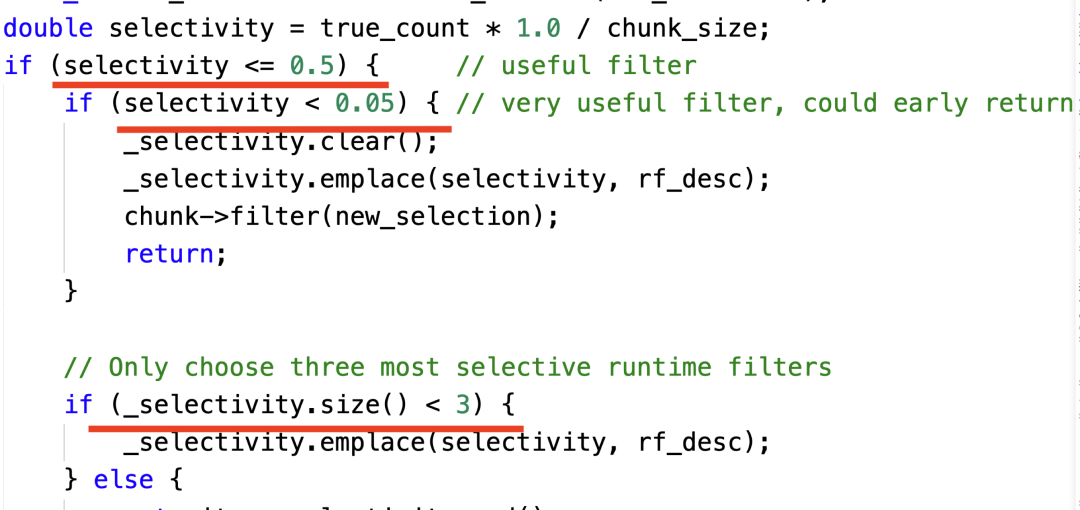
- 自适应优化:很多时候,如果我们拥有更多的上下文或者更多的信息,我们就可以做出更多针对性的优化,但是这些上下文或者信息有时只能在查询执行时才可以获取,所以我们必须在查询执行时根据上下文信息动态调整执行策略,这就是所谓的自适应优化。下图展示了一个根据选择率动态选择 Join Runtime Filter 的例子,有 3 个关键点:
a. 如果一个 Filter 几乎不能过滤数据,我们就不选择;
b. 如果一个 Filter 几乎可以把数据过滤完,我们就只保留一个 Filter;
c. 最多只保留 3 个有用的 Filter
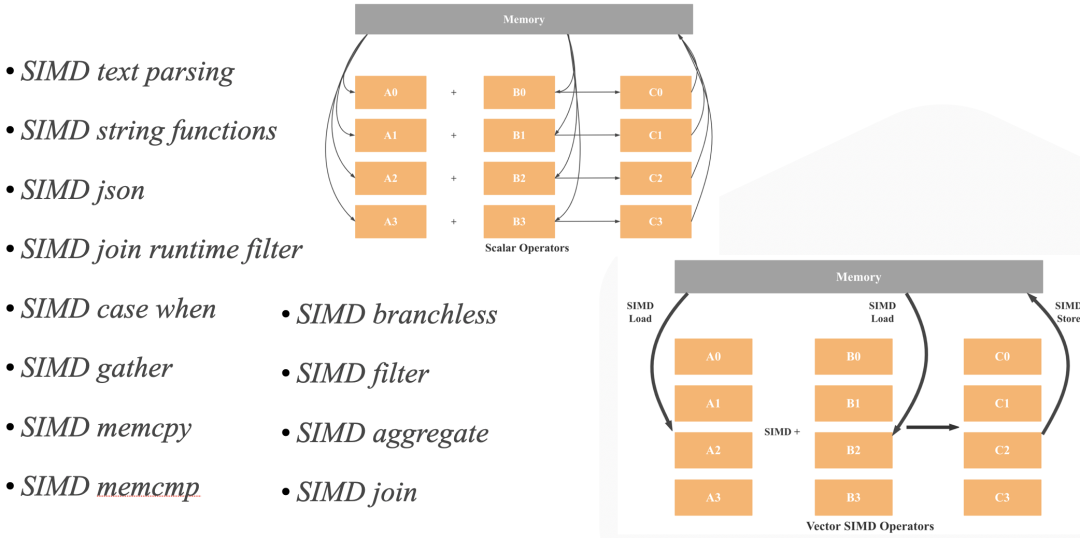
- SIMD 优化:如下图所示,StarRcoks 在算子和表达式中大量使用了 SIMD 指令提升性能。
C++ Low Level 优化:即使是相同的数据结构、相同的算法,C++ 的不同实现,性能也可能相差好几倍,比如 Move 变成了 Copy,Vector 是否 Reserve,是否 Inline, 循环相关的各种优化,编译时计算等等。
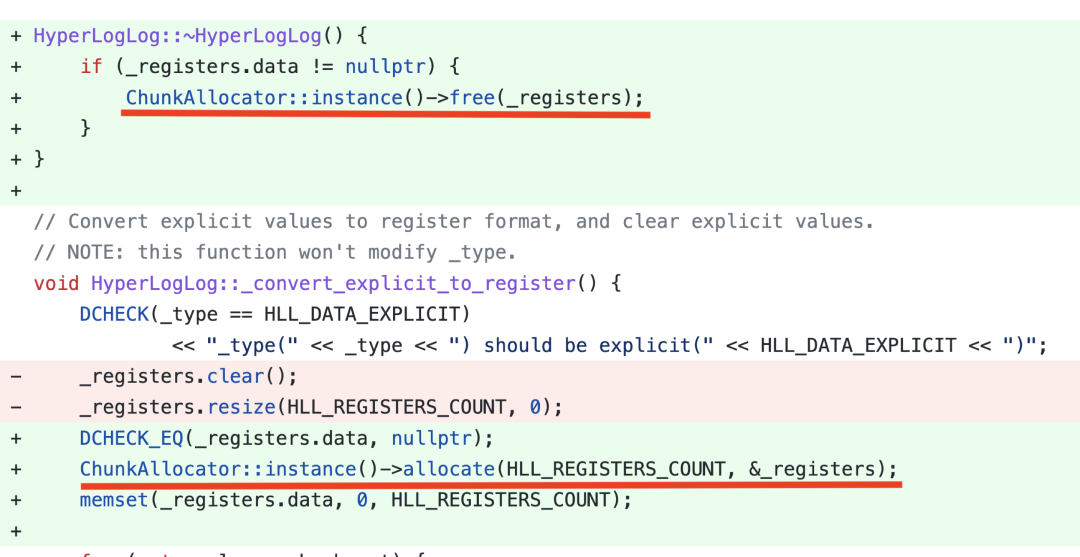
内存管理优化:当 Batch Size 越大、并发越高,内存申请和释放越频繁,内存管理对性能的影响越大。我们实现了一个 Column Pool,用来复用 Column 的内存,显著优化了整体的查询性能。下图是一个 HLL 聚合函数内存优化的代码示意,通过将 HLL 的内存分配变成按 Block 分配,并实现复用,将 HLL 的聚合性能直接提升了 5 倍。
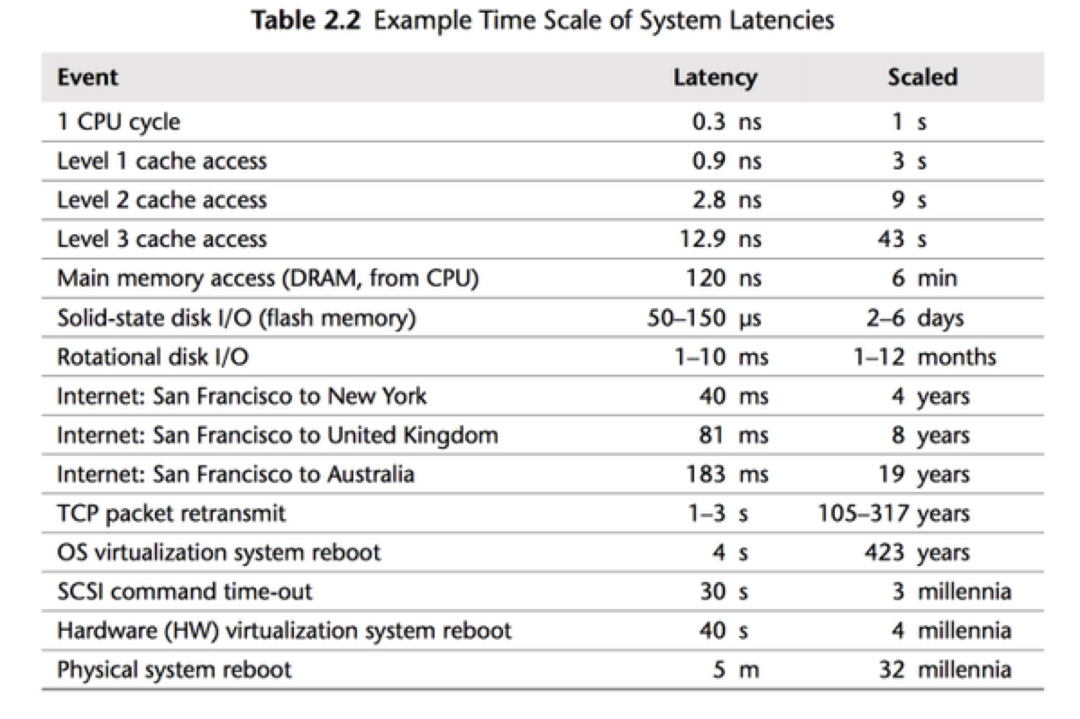
- CPU Cache 优化:做性能优化的同学都应该对下图的数据了熟于心,清楚 CPU Cache Miss 对性能的影响是十分巨大的,尤其是我们启用了 SIMD 优化之后,程序的瓶颈就从 CPU Bound 变成了 Memory Bound。同时我们也应该清楚,随便程序的不断优化,程序的性能瓶颈会不断转移。
下面的代码展示了我们利用 Prefetch 优化 Cache Miss 的示例,我们需要知道,Prefetch 应该是最后一项优化 CPU Cache 的尝试手段,因为 Prefetch 的时机和距离比较难把握,需要充分测试。
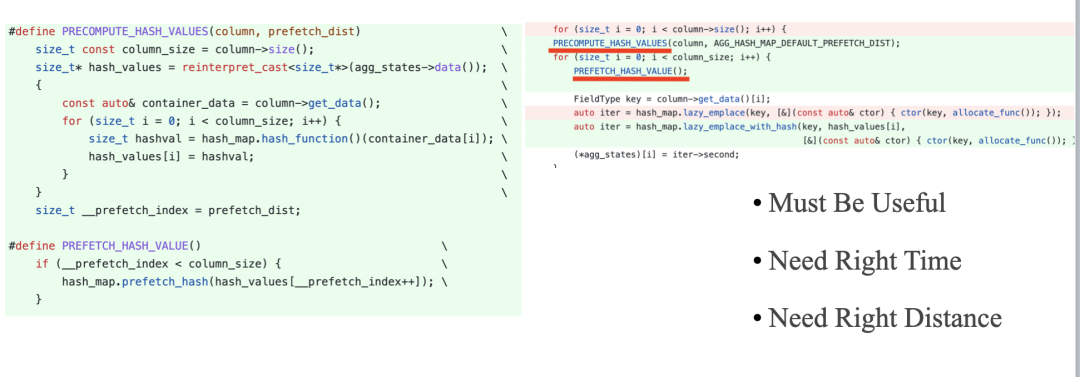
向量化执行的缺点
向量化执行相比按行执行的缺点如下:
- 更多的内存占用
- 内存更容易成为瓶颈,从而抵消向量化的好处
- 对 UDF 不友好
Pipeline 多核执行
What's pipeline
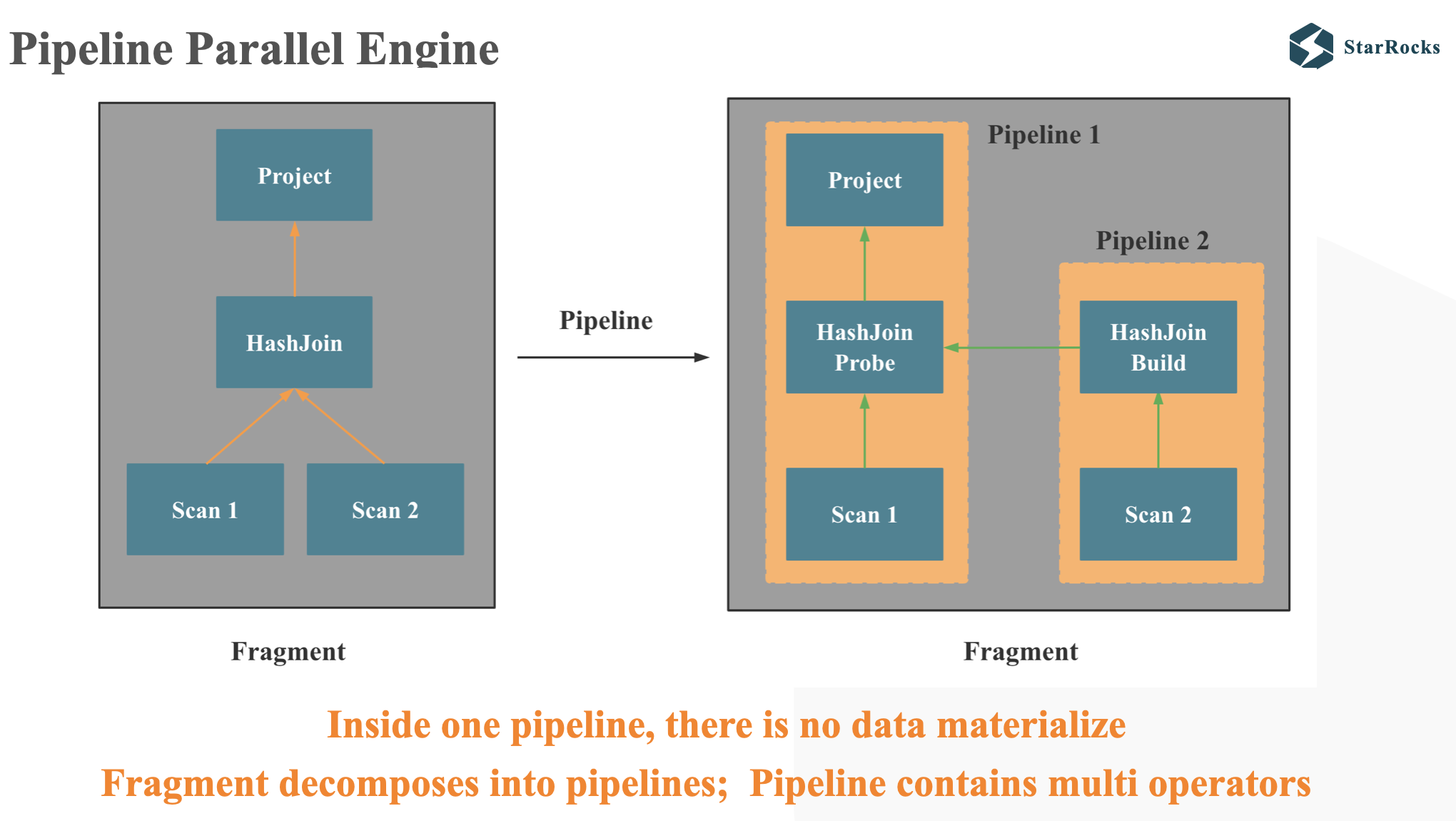
Pipeline means that an operator can pass data to its parent operator without copying or otherwise materializing the data.
Inside one pipeline, there is no data materialize, Fragment decomposes into pipelines; Pipeline contains multi operators
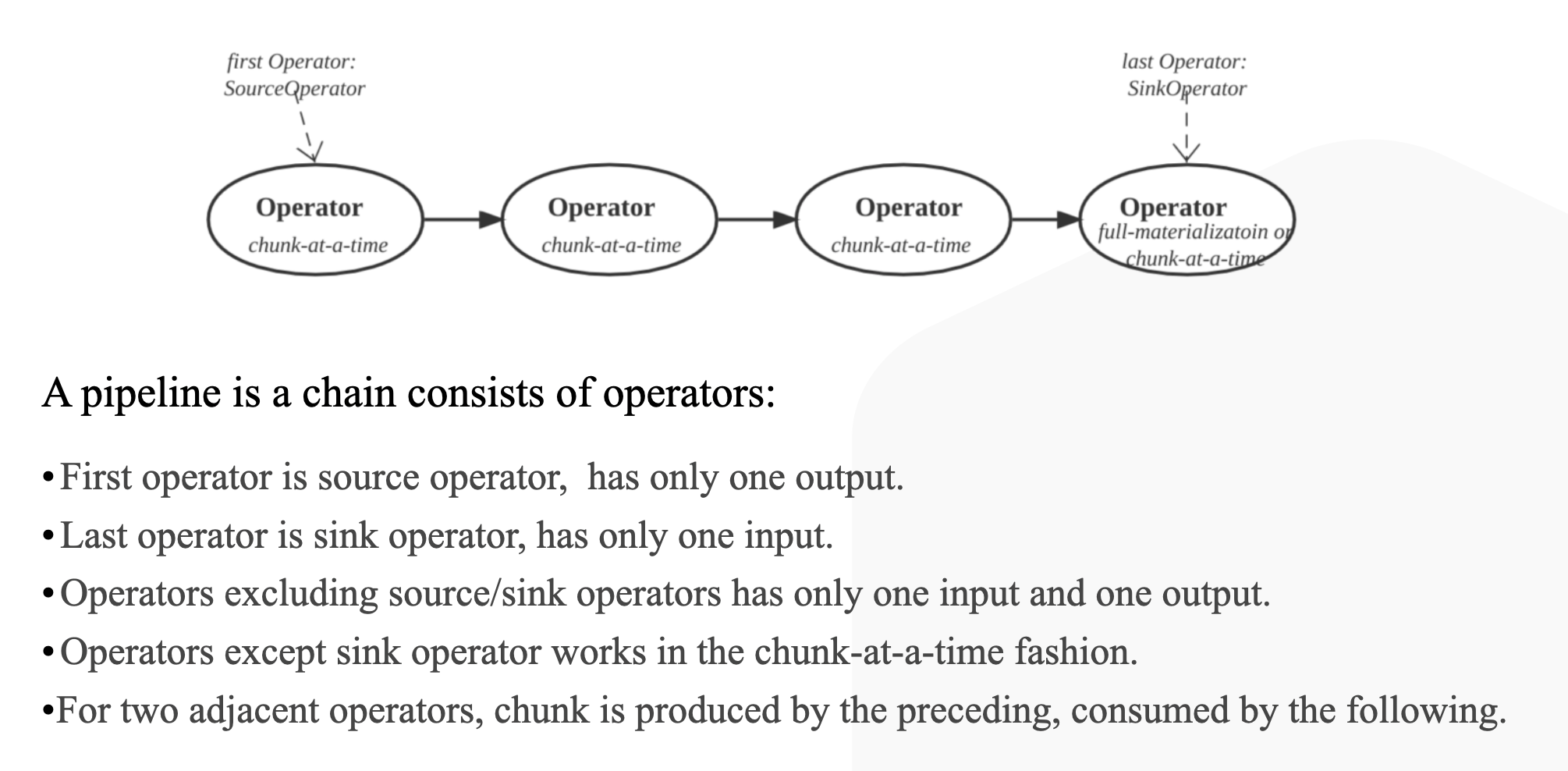
A pipeline is a chain consists of operators:
- First operator is source operator, has only one output.
- Last operator is sink operator, has only one input.
- Operators excluding source/sink operators has only one input and one output.
- Operators except sink operator works in the chunk-at-a-time fashion.
- For two adjacent operators, chunk is produced by the preceding, consumed by the following
Pipeline 引擎的关键点
- Yield
- 从内核态调度到用户态调度
- Morsel-Driven
- Task-Queue
- Operator asynchronzation
- Local Exchange
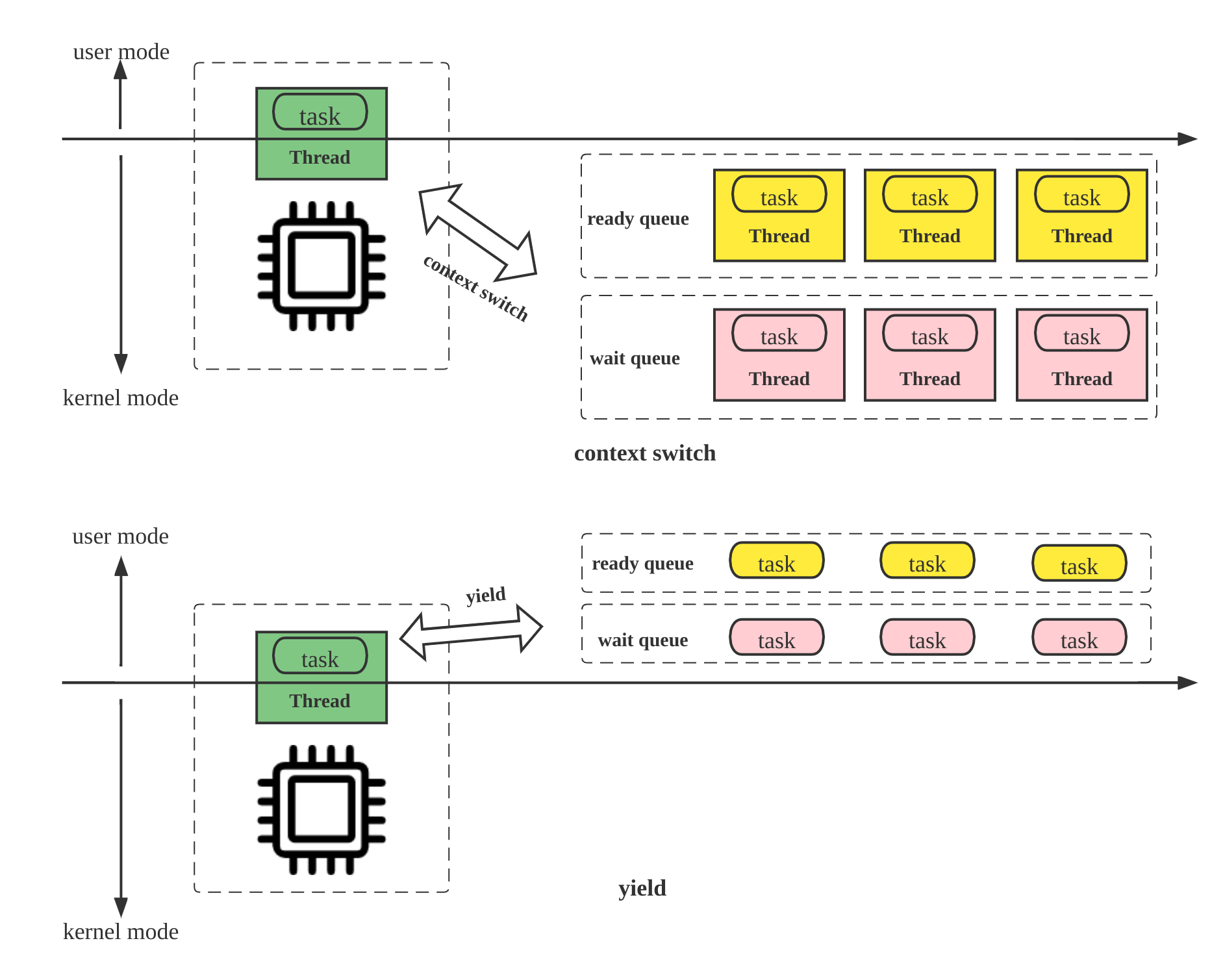
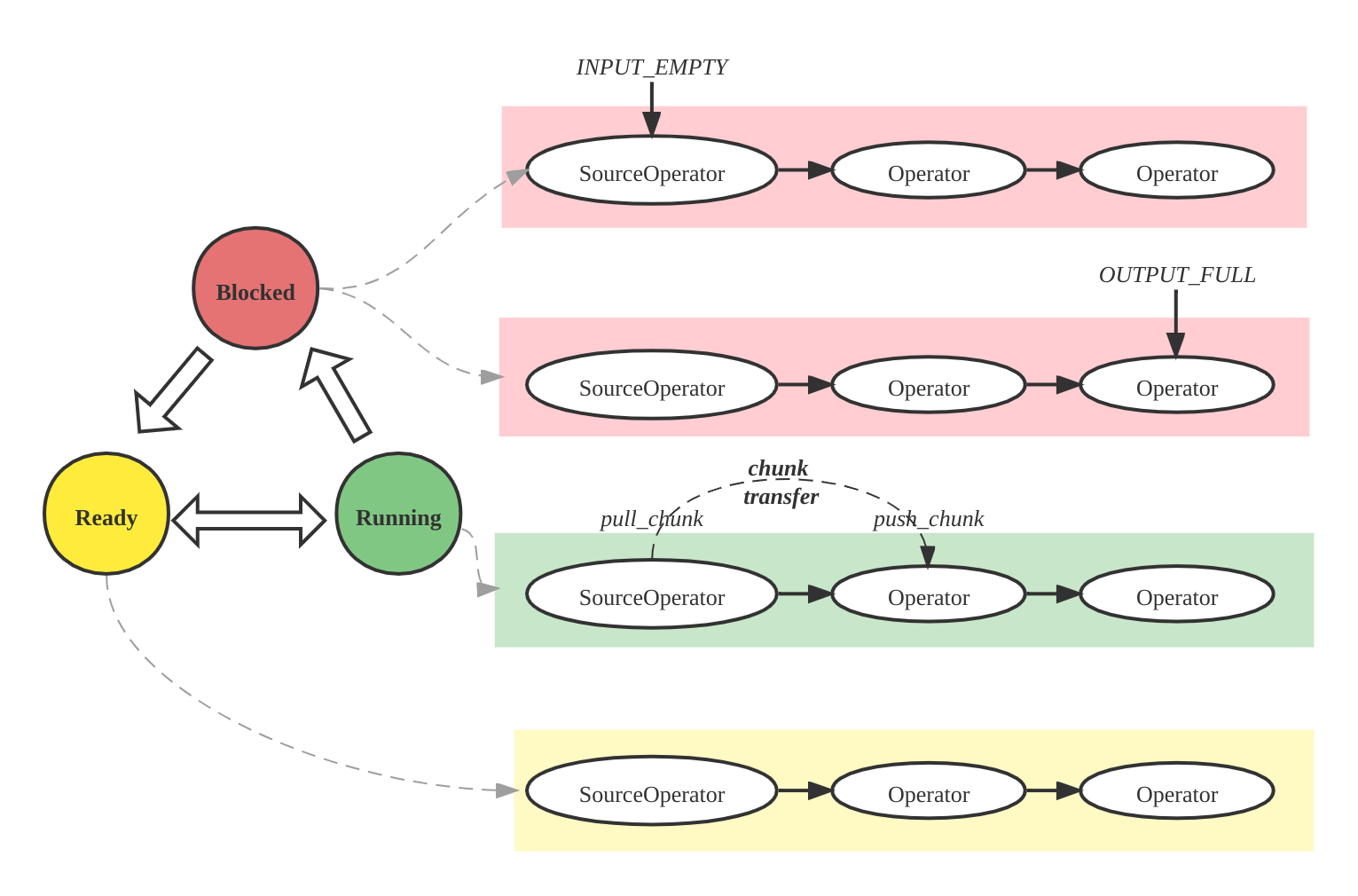
Operator 的状态
- Ready
- Running
- Blocked
MPP 多机执行
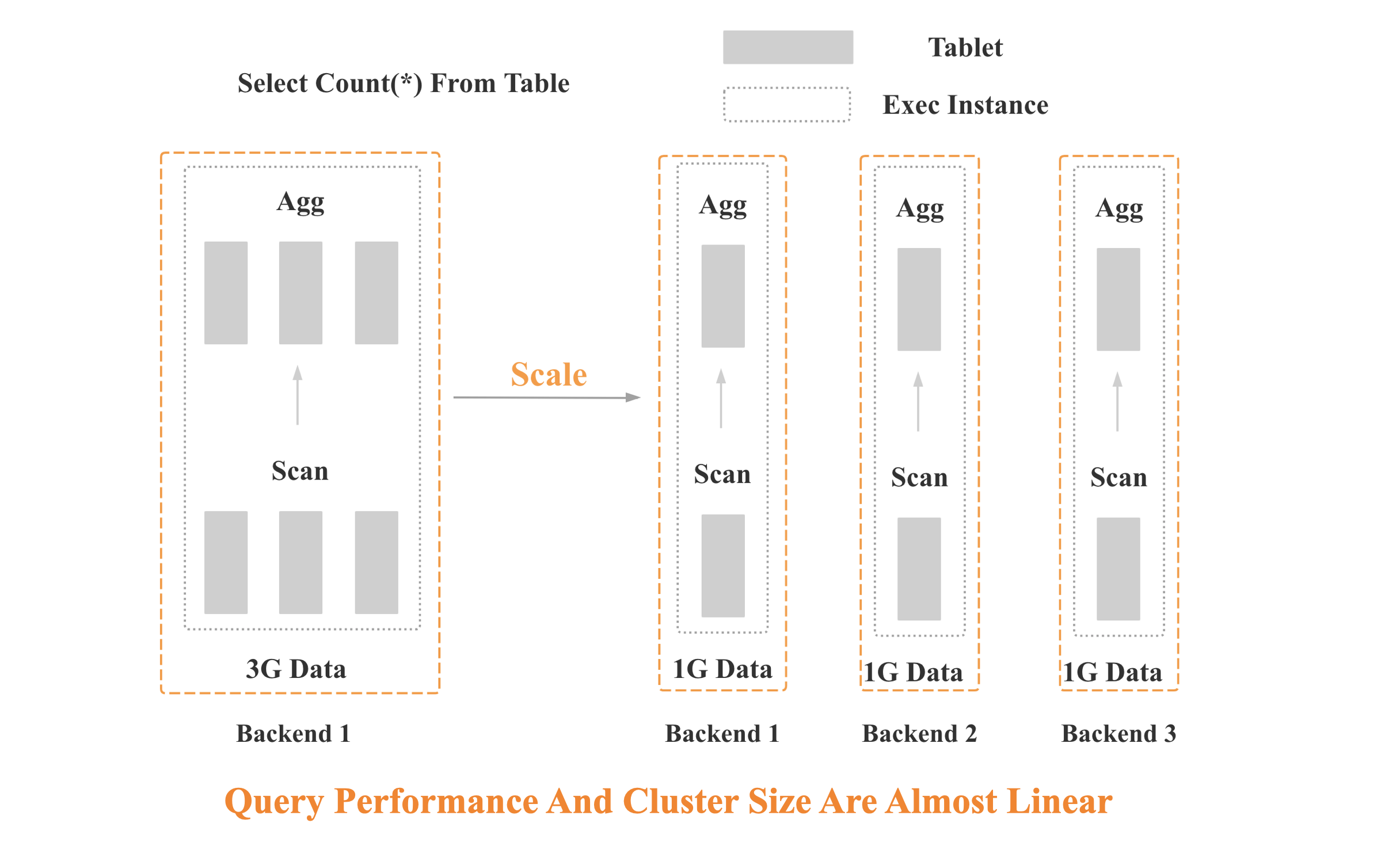
MPP 是大规模并行计算的简称,核心做法是将查询 Plan 拆分成很多可在单个节点上执行的计算实例,然后多个节点并行执行。每个节点不共享 CPU、内存、磁盘资源。MPP 数据库的查询性能可以随着集群的水平扩展而不断提升。
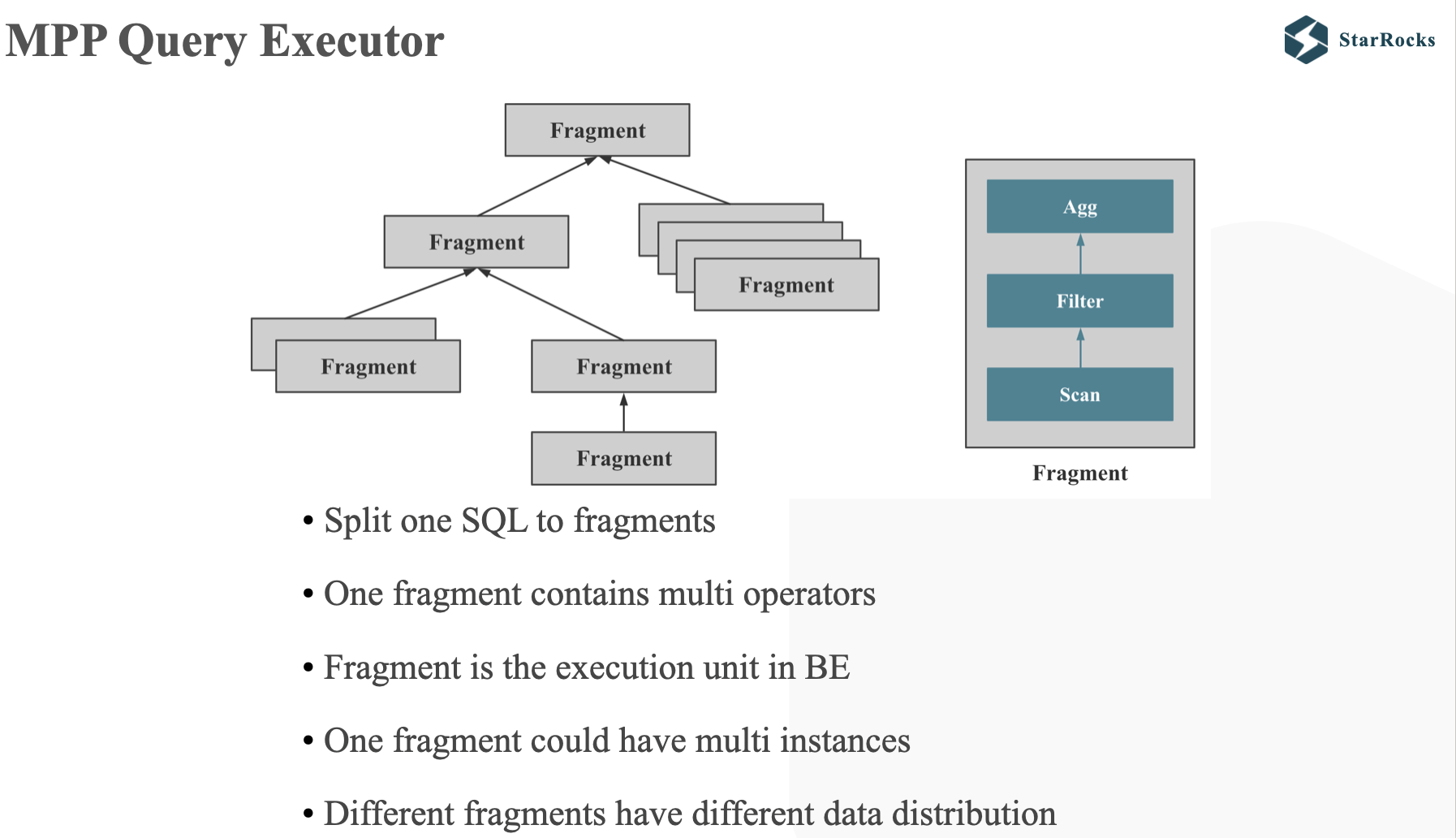
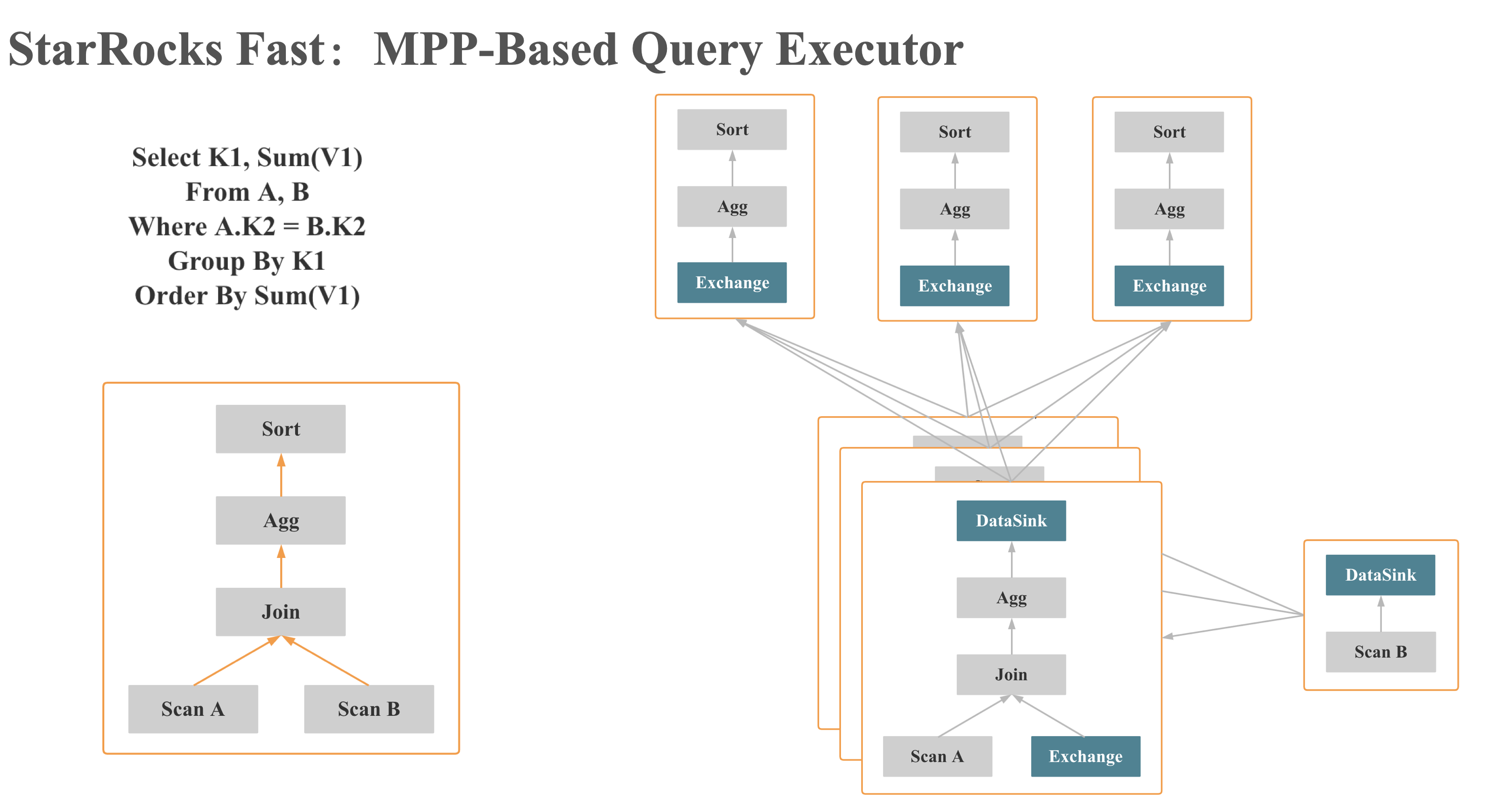
如上图 所示,StarRocks 会将一个查询在逻辑上切分为多个 Query Fragment(查询片段),每个 Query Fragment 可以有一个或者多个 Fragment 执行实例,每个 Fragment 执行实例会被调度到集群某个 BE 上执行。一个 Fragment 可以包括一个或者多个 Operator(执行算子),图中的 Fragment 包括了Scan、Filter、Aggregate。每个 Fragment 可以有不同的并行度。
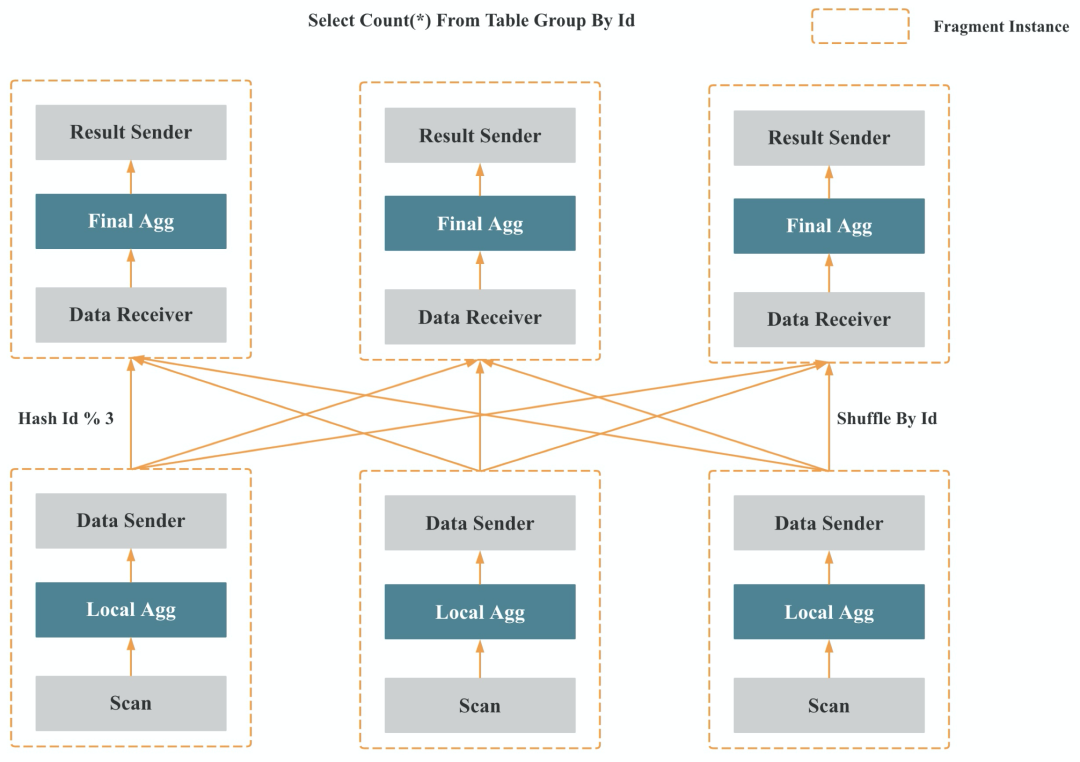
如上图 所示,多个 Fragment 之间会以 Pipeline 的方式在内存中并行执行,而不是像批处理引擎那样 Stage By Stage 执行。Shuffle (数据重分布)操作是 MPP 数据库查询性能可以随着集群的水平扩展而不断提升的关键,也是实现高基数聚合和大表 Join 的关键。
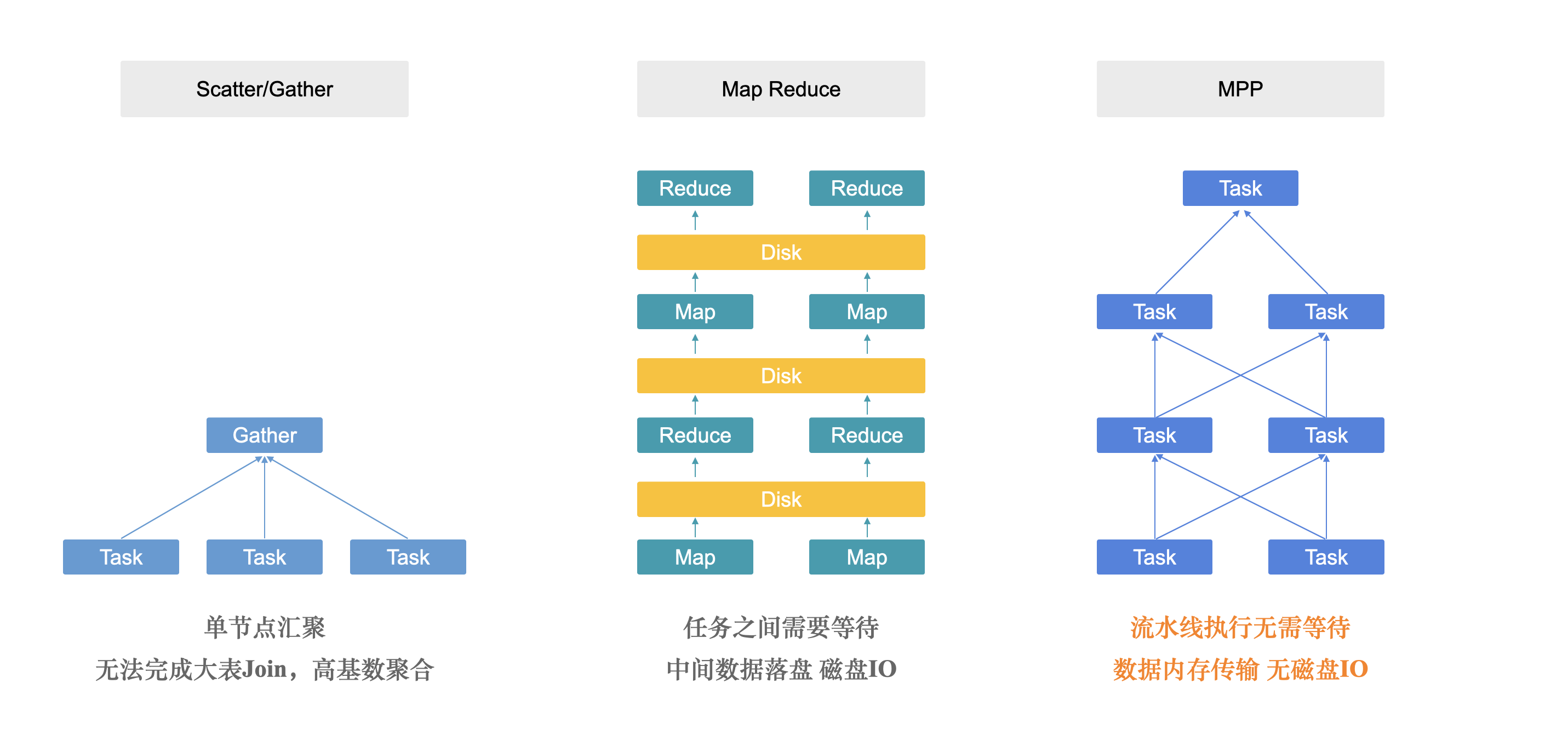
MPP VS Scatter-Gather VS Stage By Stage
MPP Scale Out
查询编译
编译什么
- 表达式计算
- Schema 解析,在提前知道Schema的情况下,可以对代码进行特化,就可以减少很多分支判断
- 多列Sort,多列聚合等算子粒度的编译执行
- 编译整个查询 Plan:针对整个查询 Plan 编译生成的代码都是紧凑的for循环,可以充分利用 CPU 的寄存器和 Cache,大幅提升效率

如何编译
Transpilation
Write code that converts a relational query plan into imperative language source code and then run it through a conventional compiler to generate native code.
JIT Compilation
Generate an intermediate representation (IR) of the query that the DBMS then compiles into native code .
- Machine code
- Virtual Machine bytecode:《Compiled Query Execution Engine using JVM》
- C++
- SQL Virtual Machine:数据库中自己实现一个VM
- LLVM IR: LLVM supports a wide variety of optimizations on the IR code like function inlining, loop vectorization and instruction combining. Further, it supports the addition of custom optimization passes.
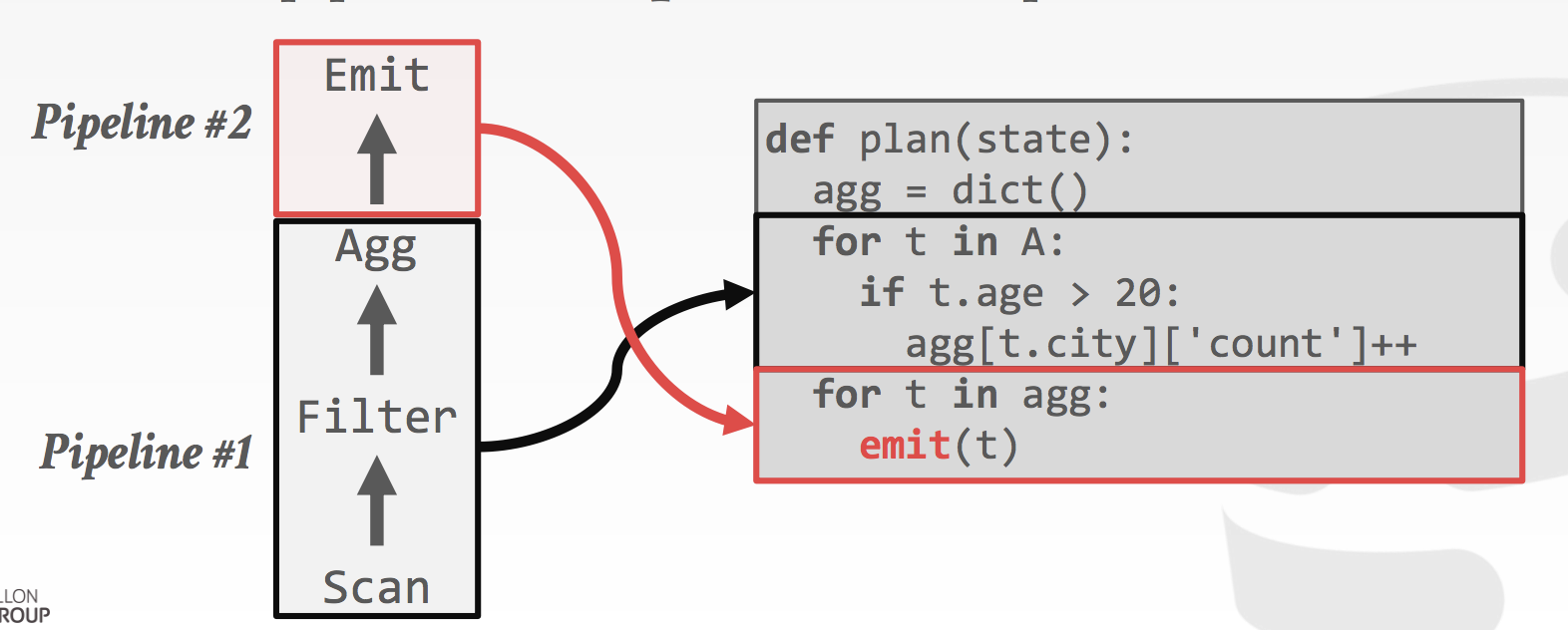
基于 Push 模型的 Code Gen 示意
In a push-based model, child operators produce and push tuples to their parents, requesting them to consume the tuples.
Conceptually each operator offers two functions:
• produce() • consume(attributes, source)
produce/consume interface 主要是为了进行代码生成,在生成的实际执行代码中并不存在。
Codegen动图: https://ericfu.me/images/2019/03/code-gen-demo-animated.gif
Operator Fusion
将多个算子的执行放到一个紧凑的循环里:
优点:避免了将数据物化到内存,可以让数据尽可能常驻 CPU 寄存器和 CPU Cache 中,进而显著提升执行效率
缺点:tuple one time 导致无法利用 SIMD
查询编译的优点
在已知表结构的情况下,手写的代码一般是最优的代码。
手写 SQL 高效的原因如下:
- No virtual function dispatches
- Intermediate data in CPU registers vs in memory
- Loop unrolling and SIMD
编译生成的代码更高效的一个重要原因还有,在通用执行引擎里面的很多“变量”,编译后都变成了 “常量”。 我们在知道用户的 SQL 的之后再 “coding”,会少很多条件判断,少很多无关代码,效率自然会高很多。
查询编译的缺点
- 编译耗时可能很长,越复杂的查询,编译时间越长
- 对 Debug 很不友好
优化点
- 先解释执行,然后异步编译查询,编译完成后,将解释执行切换到 编译好的 Native Code 执行 https://github.com/cmu-db/peloton-design/blob/master/bytecode_interpreter/bytecode_interpreter.md
- Plan Cache:将相同 pattern 的SQL 编译后的代码模板 Cache 下来,避免重复编译,可以选择 Cache 在 memory 或者 disk 上。 https://github.com/cmu-db/peloton-design/blob/master/codegen_cache/codegen_cache.md
向量化 VS 查询编译
- 两者整体的性能基本持平
- Data-centric is better for "calculation-heavy" queries with few cache misses
- Vectorization is slightly better at hiding cache miss latencies
详情参看Everything You Always Wanted to Know About Compiled and Vectorized Queries But Were Afraid to Ask 10 SUMMARY 部分
Relaxed Operator Fusion
Why Relaxed Operator Fusion
因为查询编译一般是tuple one time, 无法利用到 Vectorized 和 Prefetching 的优点。RELAXED OPERATOR FUSION 就是想同时利用到 Compilation,Vectorized 和 Prefetching 的优点。
How Relaxed Operator Fusion
为了在支持 Compilation 的同时,支持 Vectorized 和 Prefetching,就需要引入vector,所以ROF引入了 Stage 的概念,可以将一个Pipeline拆分成多个 Stage,通过stage 引入 Vector后,就可以支持 Vectorized 和 Prefetching。 如下图所示:
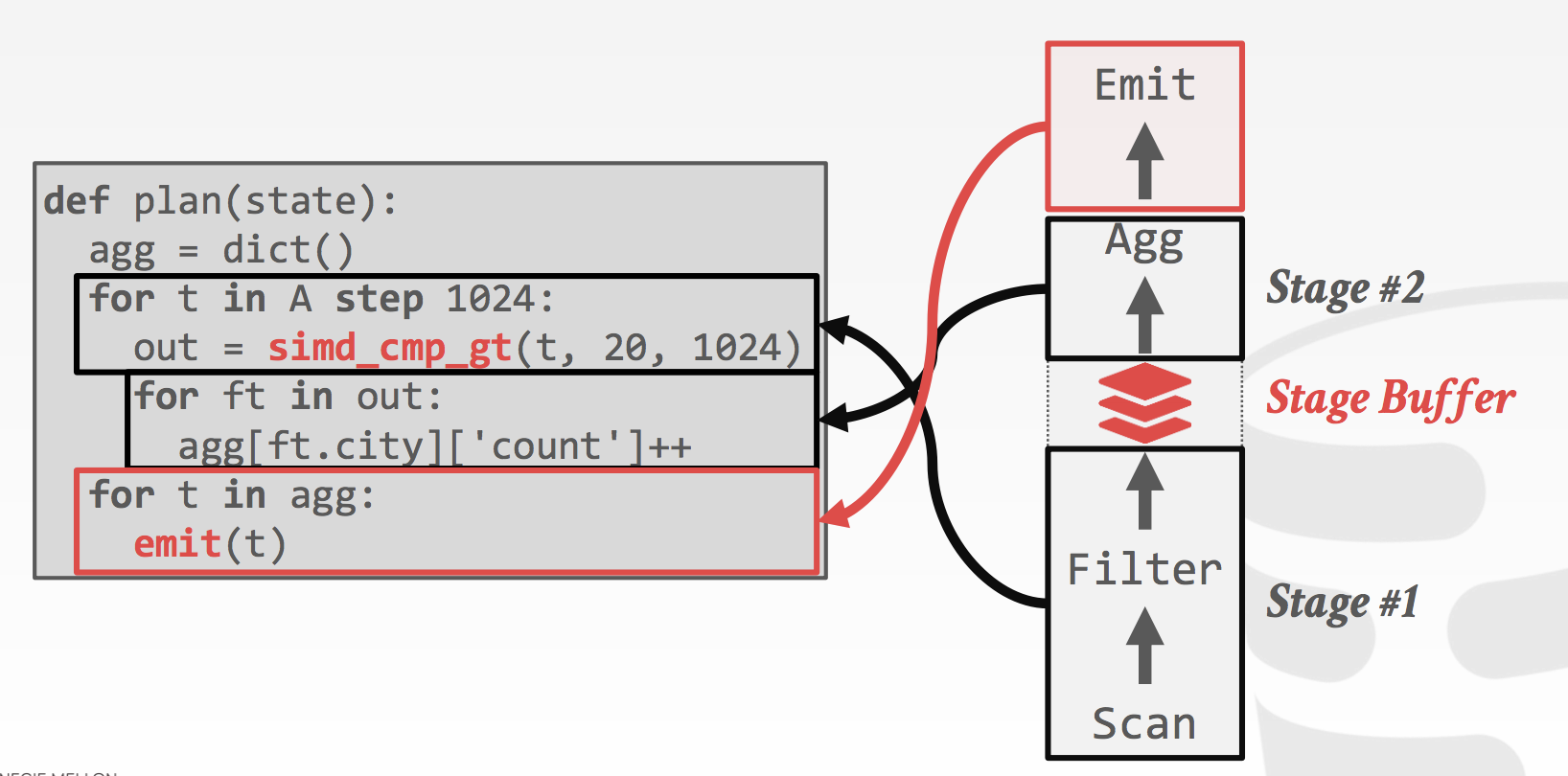
一些关键点:
- 利用 Prefetch 避免 Hash Join 大量随机访问导致的 CPU Stall
- 查询 Plan 时决定是否启用 SIMD predicate evaluation,是否启用 prefetching
- 如果一个operators里包含需要随机访问且大小超过cache size的数据结构,planner就会插入一个stage,来启用prefetching。
- Prefetch 和 SIMD vectorization 都需要一次可以处理多行数据
- SIMD vector instructions require that data be packed together contiguously
- Prefetch 不需要数据的地址连续
- In order to successfully hide cache miss latency with prefetching, the software must prefetch a number of tuples ahead (to overlap the cache miss with the processing of other tuples)
- Software prefetch instructions can move blocks of data from memory into the CPU caches before they are needed, thereby hiding the latency of expensive cache misses