查询调度器
为了能充分利用多机的资源,除了 MPP 多机并行执行框架外,查询调度器也必须能均衡多机上的负载,尽可能避免热点的出现; 为了能充分利用多核的资源,Pipeline 并行执行框架,在多核调度时也需要考虑多核上负载的均衡。
在生成查询的分布式 Plan 之后,FE 调度模块会负责 PlanFragment 的执行实例生成、PlanFragment 的调度、每个 BE 执行状态的管理、查询结果的接收。
有了分布式执行计划之后,我们需要解决下面的问题:
哪个 BE 执行哪个 PlanFragment
每个 Tablet 选择哪个副本去查询
多个 PlanFragment 如何调度
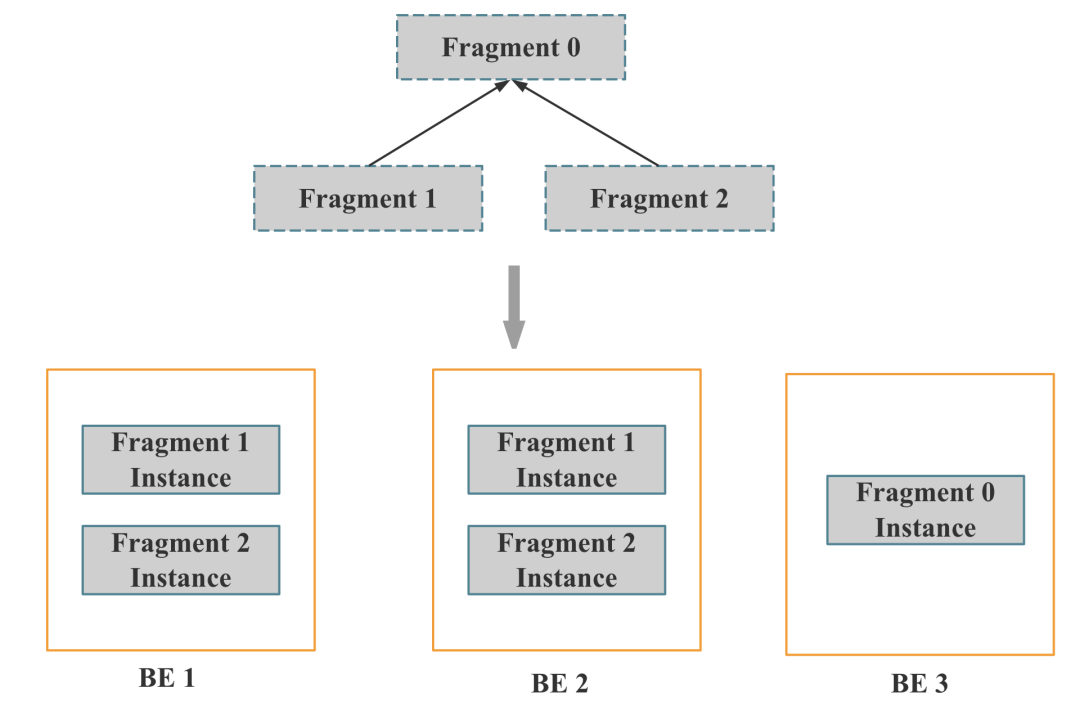
StarRocks 会首先确认 Scan Operator 所在的 Fragment 在哪些 BE 节点执行,每个 Scan Operator 有需要访问的 Tablet 列表。然后对于每个 Tablet,StarRocks 会先选择版本匹配的、健康的、所在的 BE 状态正常的副本进行查询。在最终决定每个 Tablet 选择哪个副本查询时,采用的是随机方式,不过 StarRocks 会尽可能保证每个 BE 的请求均衡。假如我们有 10 个 BE、10 个 Tablet,最终调度的结果理论上就是每个 BE 负责 1 个 Tablet 的 Scan。
当确定包含 Scan 的 PlanFragment 由哪些 BE 节点执行后,其他的 PlanFragment 实例也会在 Scan 的 BE 节点上执行 (也可以通过参数选择其他 BE 节点 ),不过具体选择哪个 BE 是随机选取的。
当 FE 确定每个 PlanFragment 由哪个 BE 执行,每个 Tablet 查询哪个副本后,FE 就会将 PlanFragment 执行相关的参数通过 Thrift 的方式发送给 BE。
目前 FE 对多个 PlanFragment 调度的方式是 All At Once 的方式,是按照自顶向下的方式遍历 PlanFragment 树,将每个 PlanFragment 的执行信息发送给对应的 BE。
多资源多任务的统一调度