如何寻找性能瓶颈点
一方面可以通过数据库系统内置的性能优化工具或者可观测性工具去找到瓶颈点,另一方面可以通过 Linux 通用的性能测试工具来寻找瓶颈点。
3.1 StarRocks Observability : Query Profile
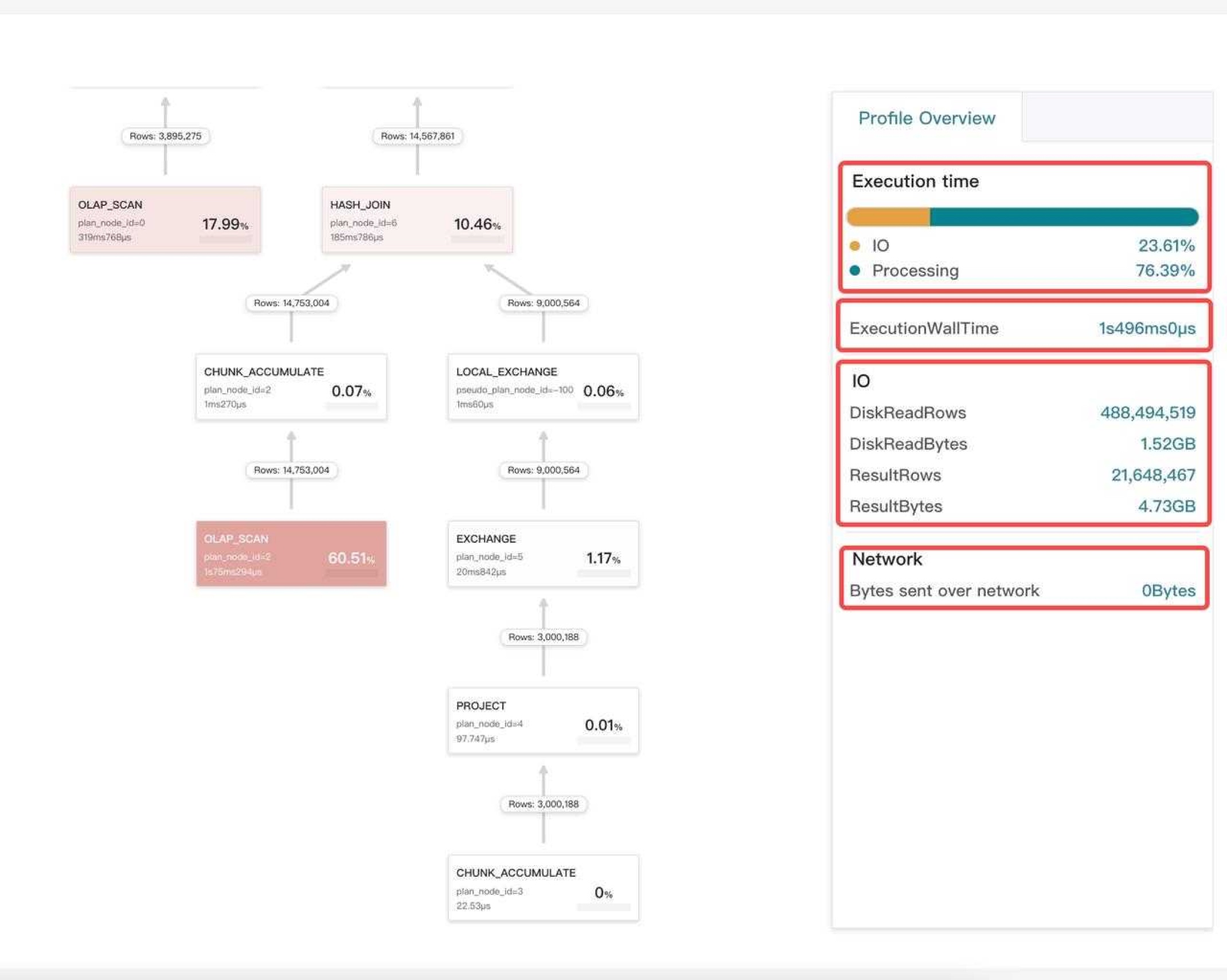
如上图所示,查询 Profile 是我们发现性能瓶颈点最常用的工具,从 Profile, 我们可以知道一个查询是慢在 plan 阶段,还是执行阶段,也能知道是哪个算子是执行瓶颈。
从每个算子的关键性能指标,我们也可以知道慢的原因。
常见的瓶颈点:
- 数据倾斜:关键同一个算子,或者同一个指标在不同机器实例的最大,最小值
- 是否触发分区分桶裁剪
- 是否命中期望的MV 或者 Rollup
- 谓词是否下推到存储层
- 谓词是否用到索引
- Join 的左右表顺序是否正确,是否是用小表构建 Hash 表
- Join 的分布式执行策略是否正确:Shuffle Join, Bucket Shuffle Join, Broadcast Join, Colocate Join, Replication Join
- 是否生产了 Runtime Filer, Runtime Filer 是否下推到存储层
- 是否有大量的网络数据传输
- 是否 Compaction 不及时导致文件数太多
- 并行度是否足够,是否用到了所有机器的资源,每个机器是否用到多核的资源
3.2 StarRocks Observability : Optimizer Trace
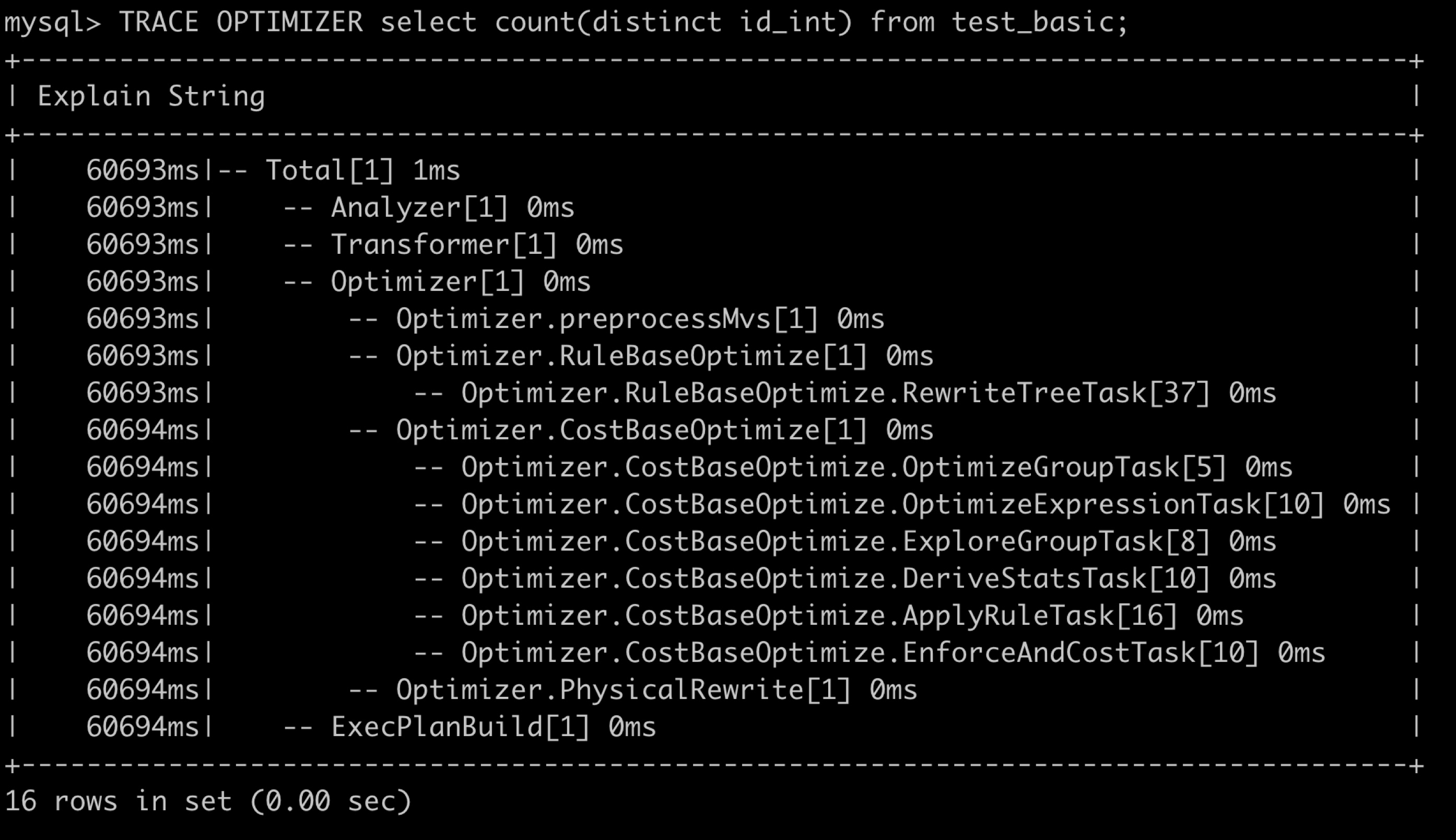
如上图所示,我们通过一个命令就可以知道 StarRocks 优化器到底慢在哪一个阶段,可以快速定位出优化器阶段的性能瓶颈。
3.3 StarRocks Observability : Executor Trace
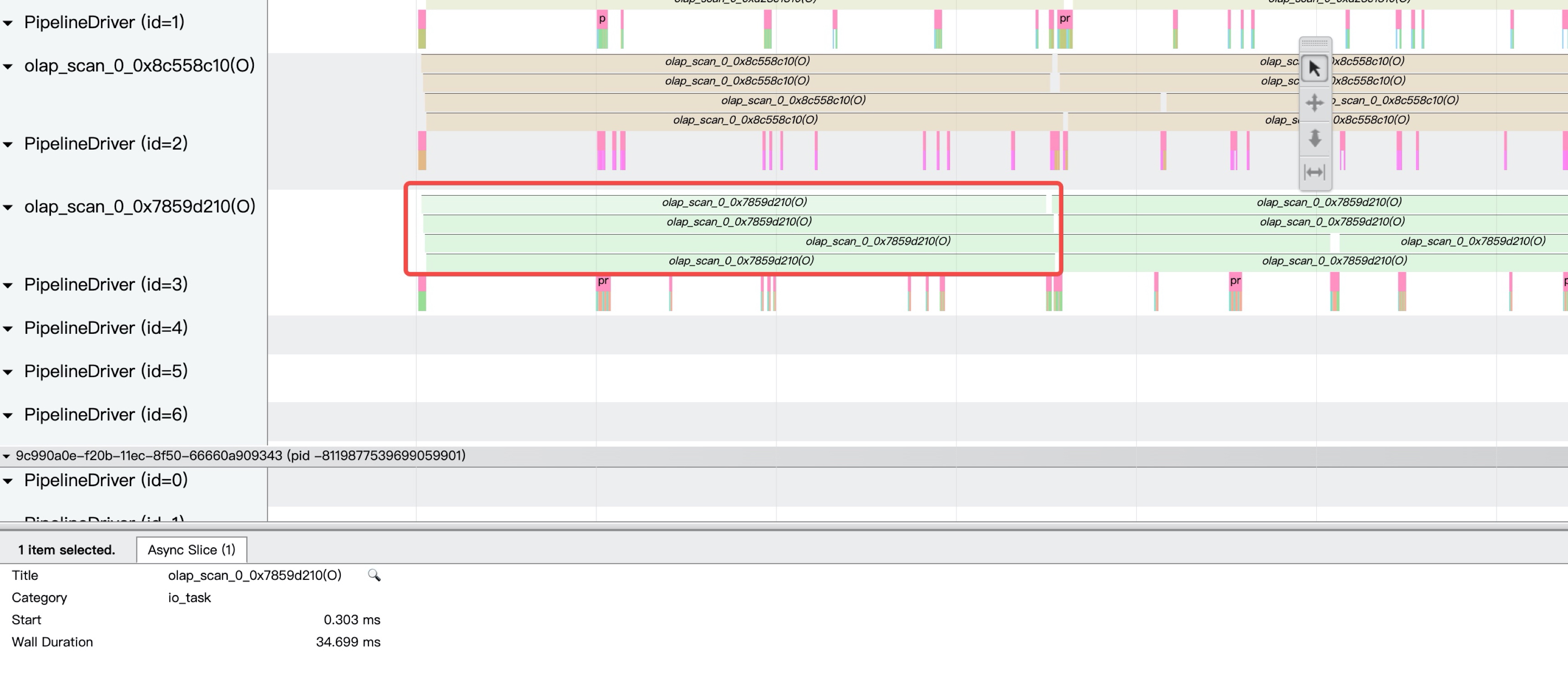
如上图所示,我们可以通过 StarRocks 的执行器的 trace 工具快速定位出执行层到底是慢在哪个点,比如是CPU的问题,IO的问题,还是调度框架的问题。
3.4 CPU Sampling —— Perf
除了数据库系统自身的工具,我们也可以使用 Linux 通用的性能 profile 工具,比如,最常见的性能 Profile 工具,Perf,可以通过火焰图看成 CPU 热点。 详情大家可以参考: https://www.brendangregg.com/perf.html
3.5 Off CPU Tracing —— eBPF
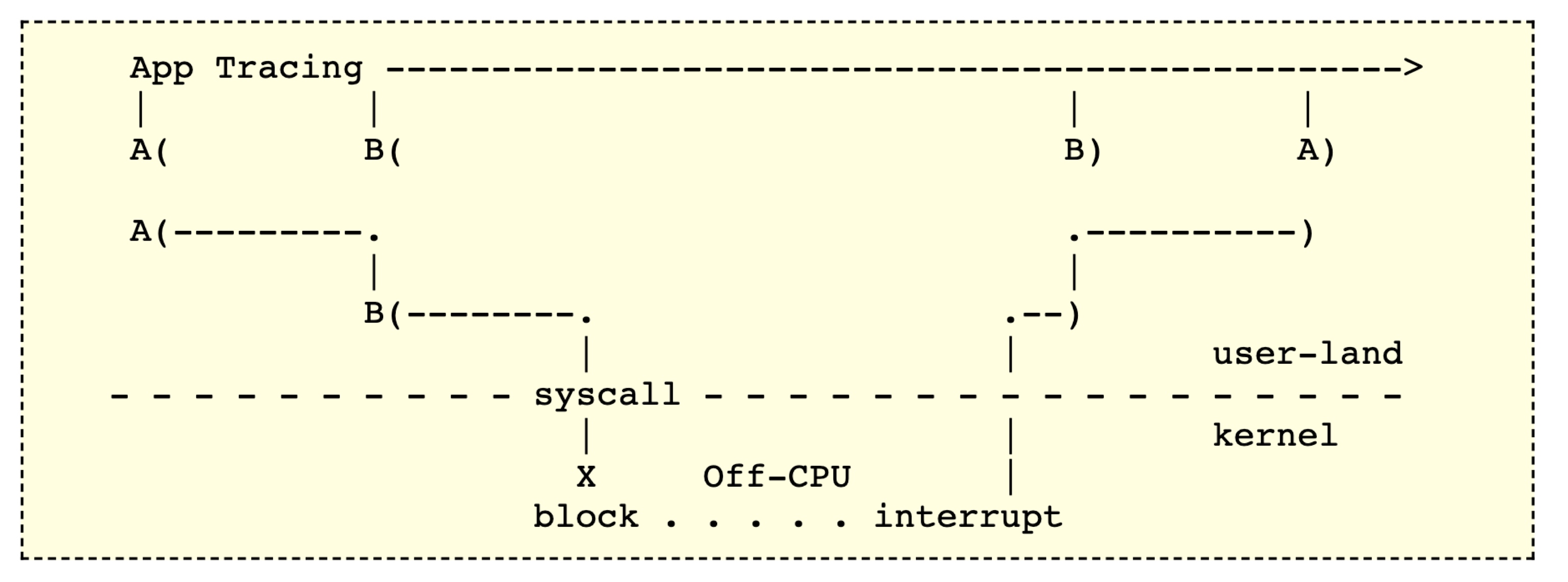
很多时候,性能的瓶颈并不是在 CPU 执行本身,而是在 IO,网络,Lock 上,这时候我们就需要进行 Off CPU 分析,而且这时候基于 Sampling 的性能工具往往没有效果,我们需要使用基于 Trace 的 性能工具,比如 eBPF。详情大家可以参考 https://www.brendangregg.com/offcpuanalysis.html
https://danluu.com/perf-tracing/
动态追踪的事件源根据事件类型不同,主要分为三类。静态探针,动态探针以及硬件事件。
3.6 Intel 的 Top-down 分析方法
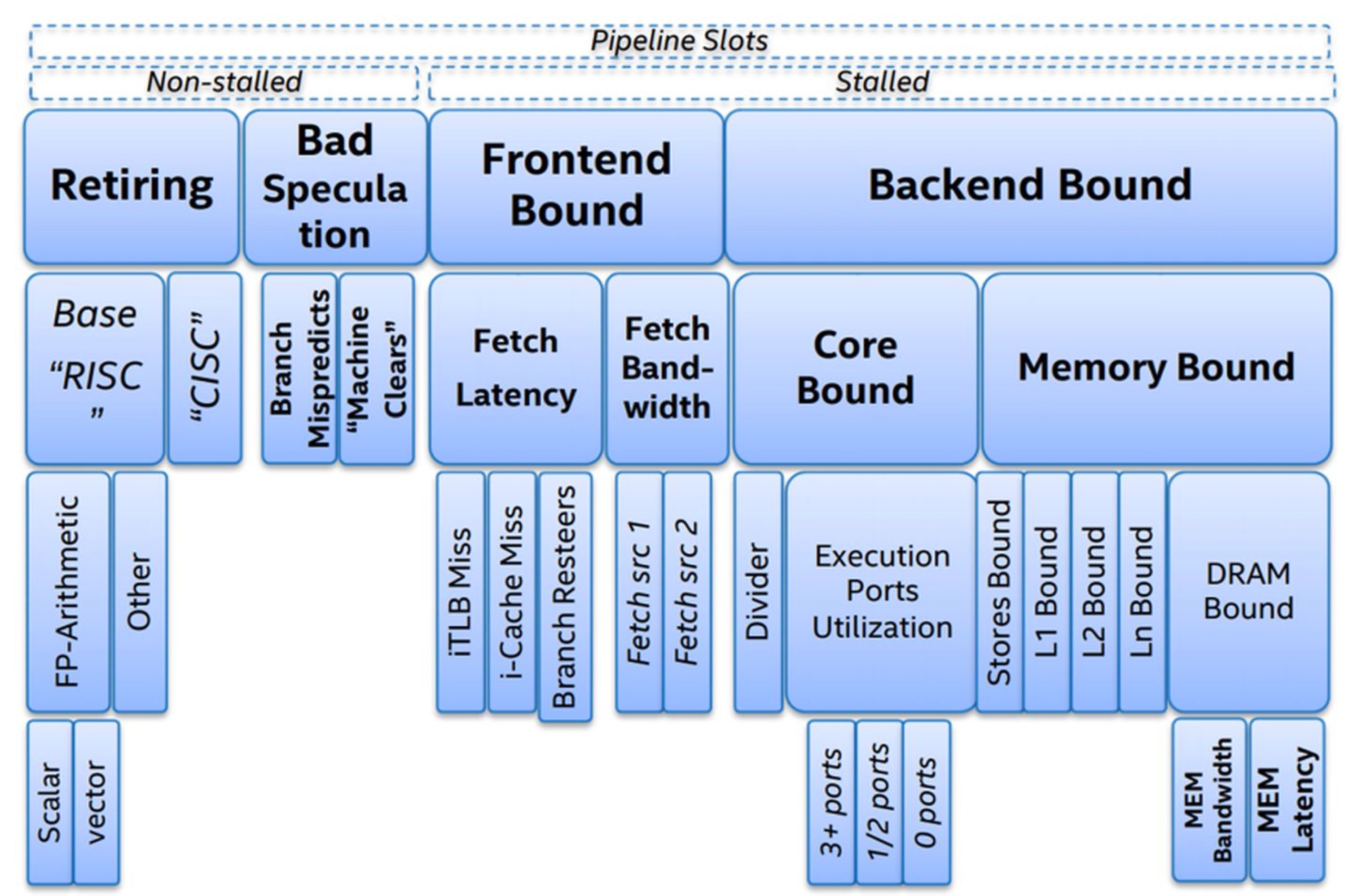
如上图所示,Intel 基于 CPU 执行的整个过程,提出了 《Top-down Microarchitecture Analysis Method》的 CPU 微架构性能分析方法,将 CPU 执行的可能瓶颈点分为4大类,然后每一类在不断细分,层层深入,定位到最具体的性能瓶颈点。
为了便于大家理解,我们可以将上图简化为下图(不完全准确):
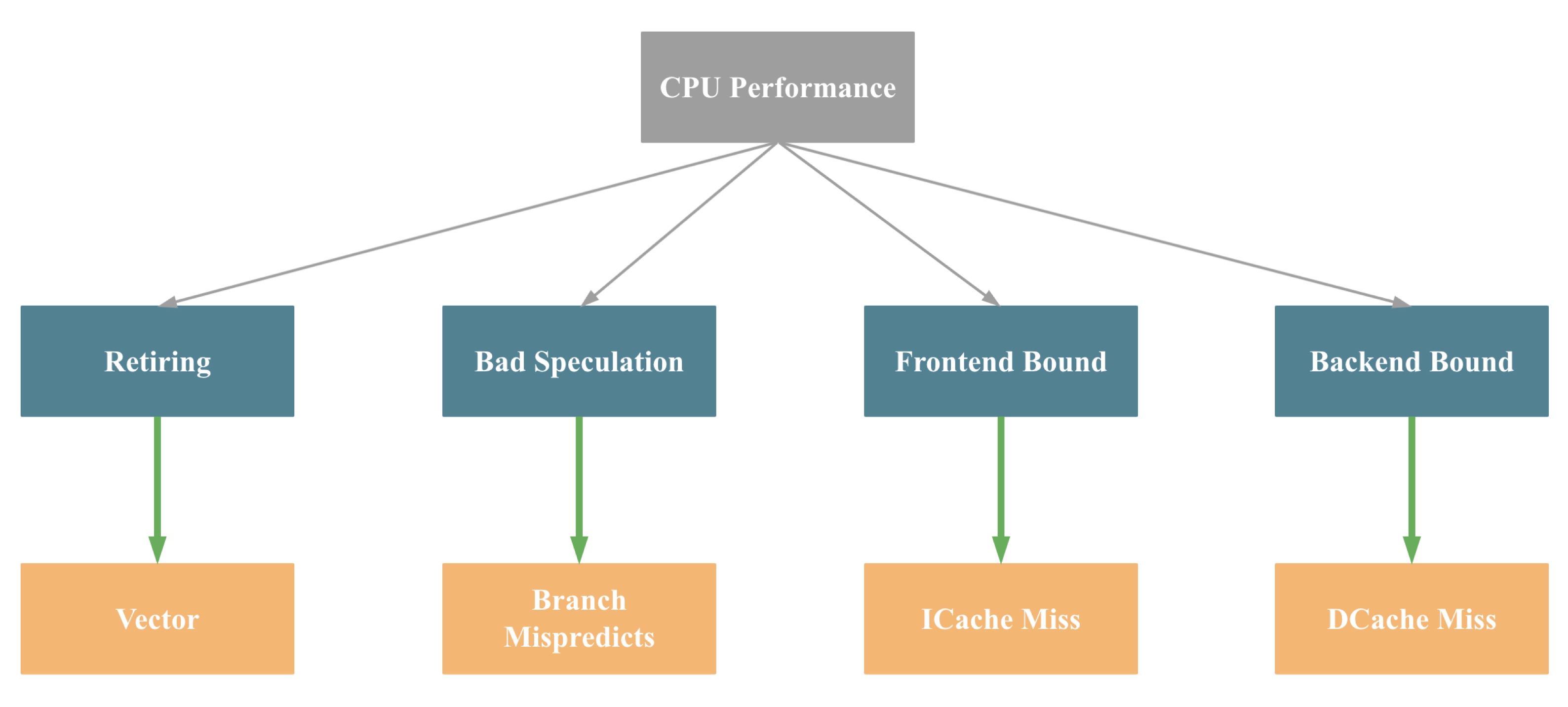
即影响一个 CPU 程序的性能瓶颈主要有4大点:Retiring、Bad Speculation、Frontend Bound 和 Backend Bound,4个瓶颈点导致的主要原因(不完全准确)依次是:缺乏 SIMD 指令优化,分支预测错误,指令 Cache Miss, 数据 Cache Miss。
3.7 Linux Performance tools
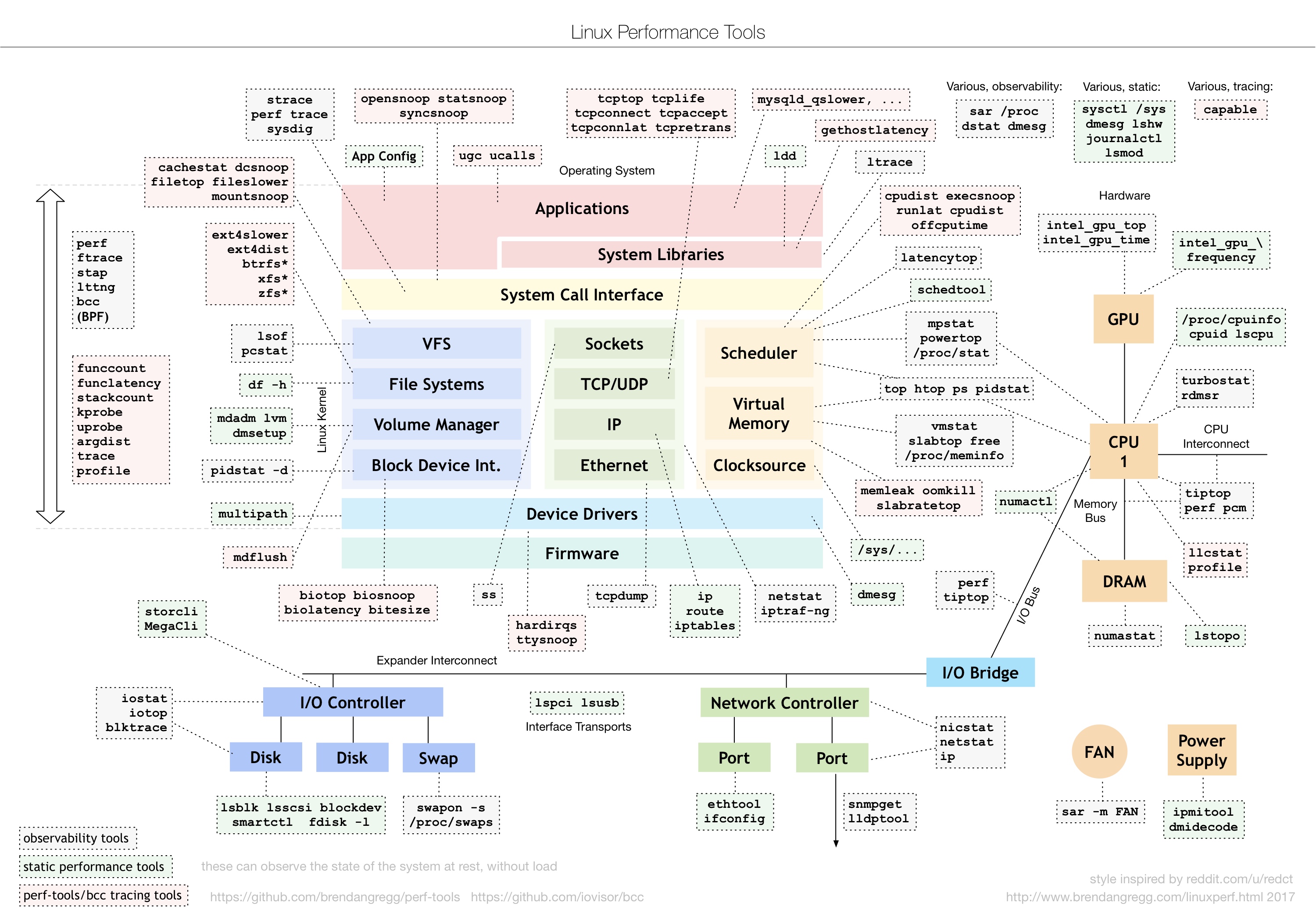
如上图所示,操作系统每个模块的问题都有对应的工具可以进行分析,大家在日常工作中就需要不断积累,清楚哪类问题可以用哪些工具解决,也要清楚每个重要工具可以解决哪些问题。
3.8 性能监控指标
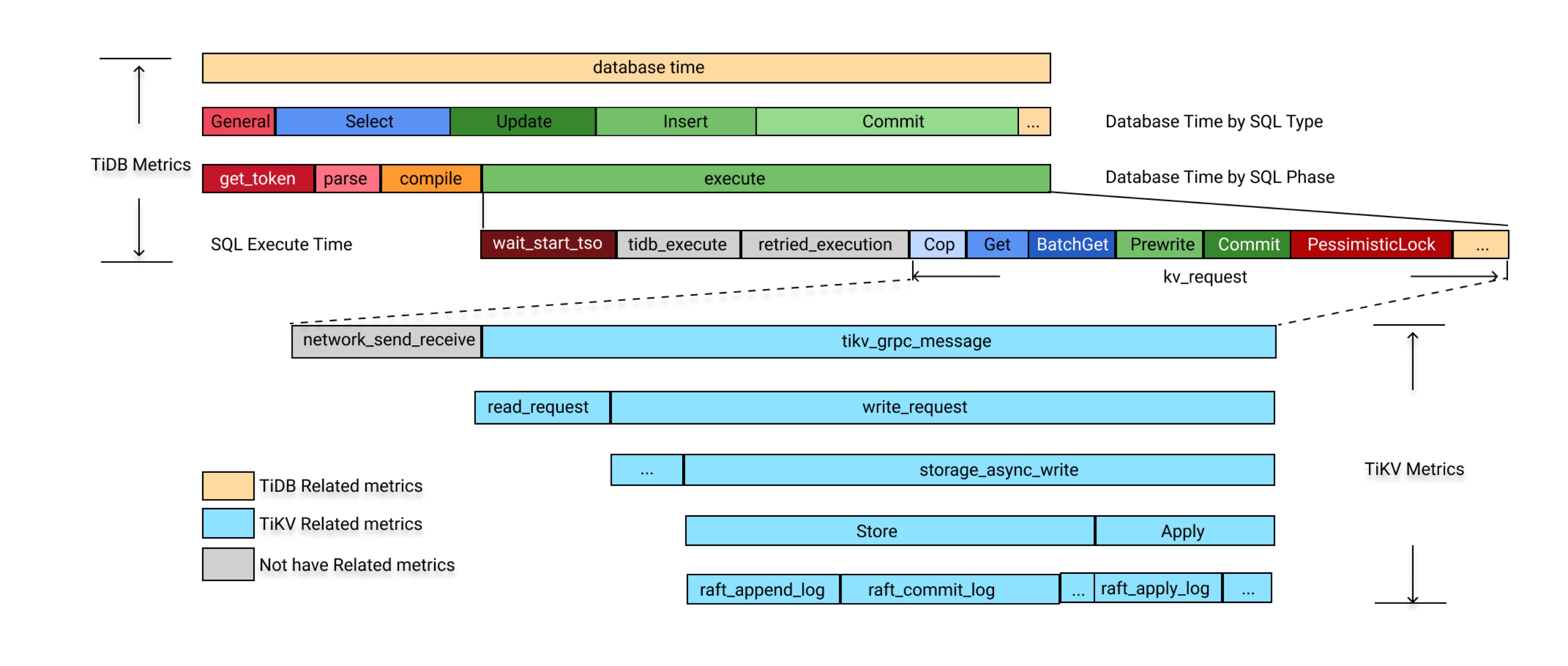

这一点上 TIDB 做的比较好,整个查询过程的关键性能指标都暴露出来,可以比较方便的分析某类问题的性能瓶颈,主要是对DBA,解决方案,普通用户更加友好。 详情可以参考 https://docs.pingcap.com/tidb/dev/performance-tuning-methods
3.9 优化器 Plan Test
SQL 是声明式,只告诉了 What,没有告诉 How, 所以一个 SQL 的执行路径可能成千上万,优化器选择出的最终 Plan 往往不是最优的,我们研发有时候也不能判断哪种执行计划是最优的。 主要是两个原因: 1是执行计划很多,人很难枚举,2是执行计划的真实执行性能是和执行器每个算子的性能,集群规模,数据特点,硬件资源等都有关系。 所以我们需要有专门的优化器 Plan 测试工具去枚举测试 不同执行计划的真实性能,从而发现更优的执行计划。

如上图所示,上面两个SQL 等价,但是很多数据库的对于第二个SQL 却无法推断出 ename not like 'ACCT' 这个谓词, 导致有3倍的性能差距。
下面两个 SQL,如果有 emp_pk 是主键的信息,group by emp_pk 也可以直接优化掉,性能就可以提升3倍。