预计算 VS 现场计算
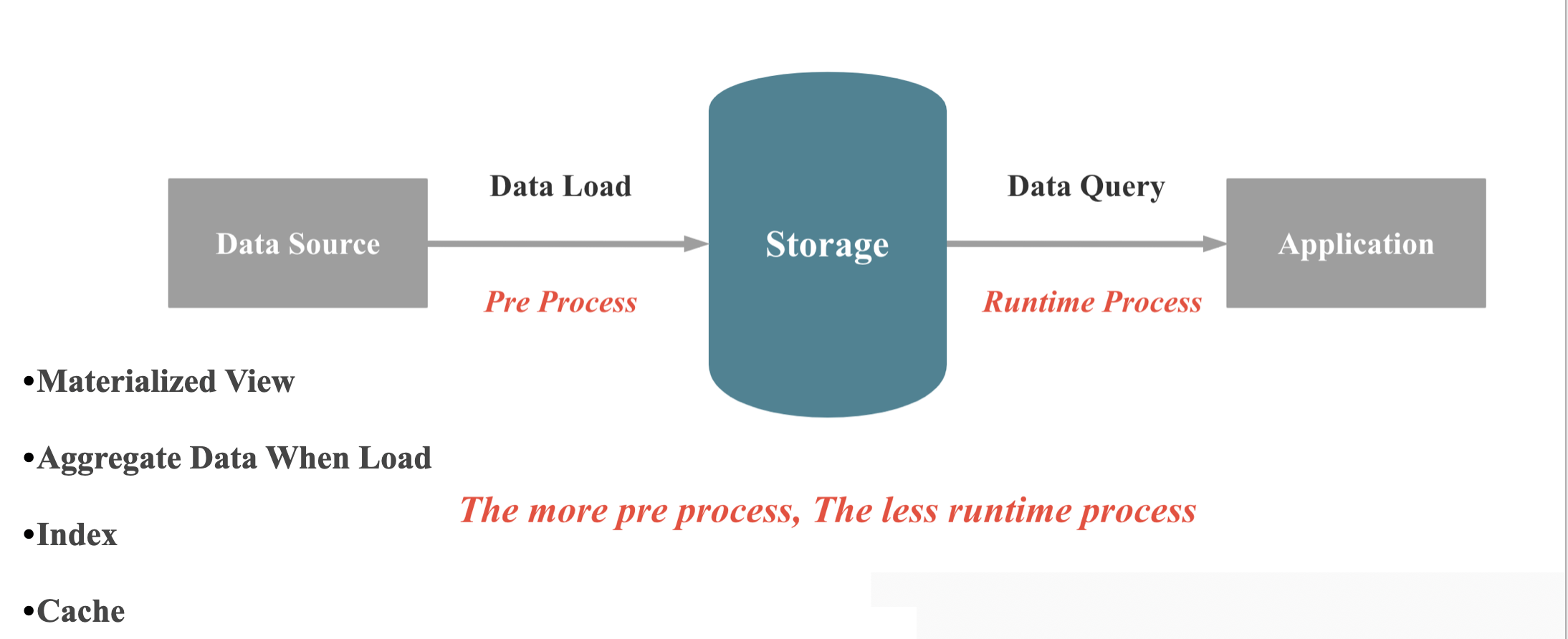
数据库本质上来讲,就是在做两件事情: 数据的存储 和 数据的查询,当数据写入数据库,数据库保证数据不会丢,当我们需要查询或者分析数据时,数据库可以快速,正确地返回我们想要的数据。 如上图所示,在数据库现场计算能力不变的情况,要提升查询性能,我们就有两种大的手段:1,在数据库导入过程,进行一些预处理,减少现场计算的成本; 2,在数据存储时,有空间换时间,减少现场计算的成本。 具体可以分为4类手段:
1.1 Materialized View
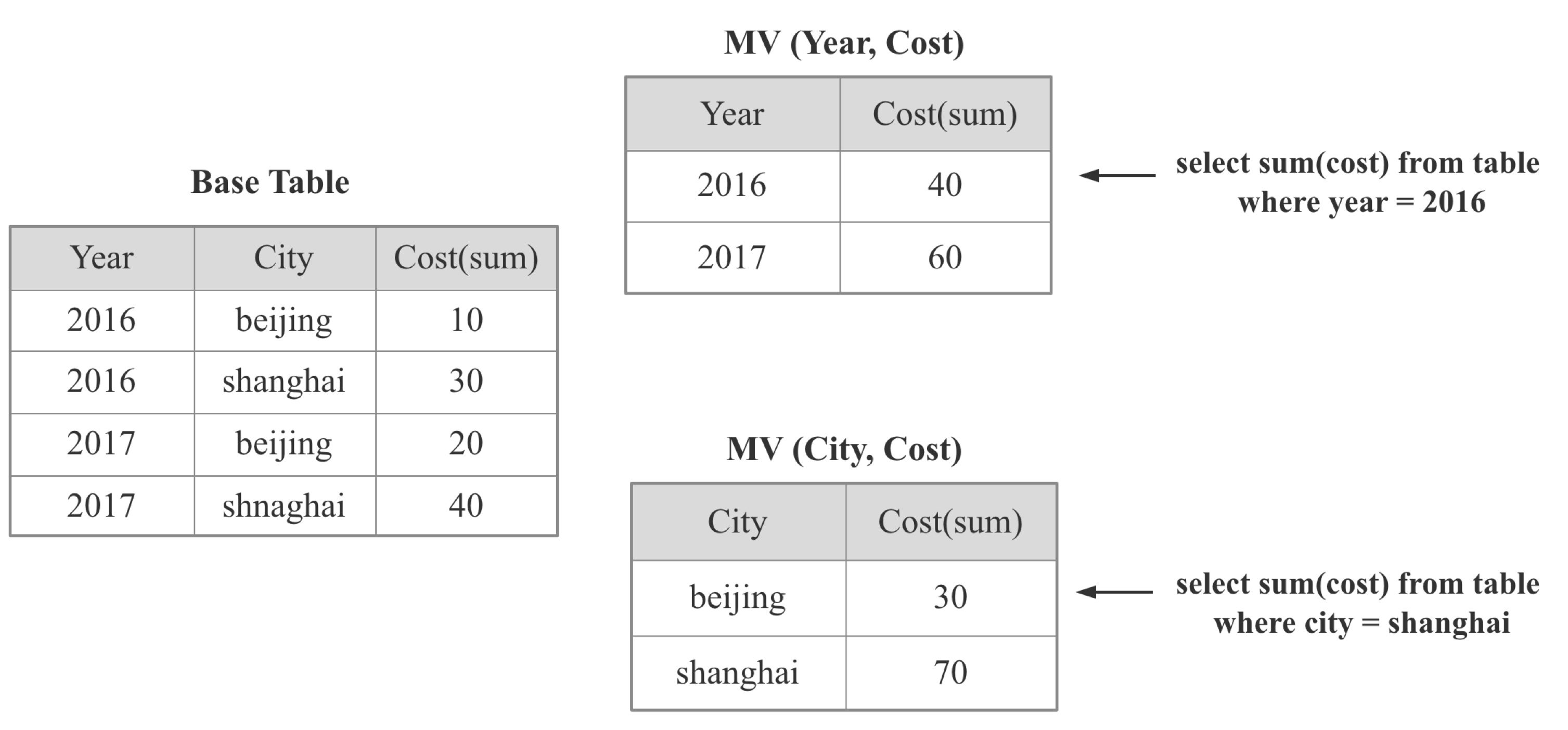
如上图所示:物化视图就是将某个或者某类SQL的查询结果提前计算出来,用导入时延,存储成本换取查询时的高性能。物化视图是 OLAP 数据库的常见加速手段,比如:
- StarRocks 中的 物化视图
- Google Mesa 中的 Rollup
- Apache Kylin 中的 Cube
- Apache Pinot 中的 Star-Tree Index
- Apache Calcite 中的 Lattice
- Dremio 中的 Reflections
物化视图技术涉及的关键点如下:
- 物化视图模型如何表达
- 如何决定对哪些View 或者 SQL 进行物化:一般情况下,只需要少量的物化视图就可以加速大量的查询
- 物化视图的维护: 当 Base 表更新时,物化视图如何进行有效地更新,如何实现增量更新,如何支持多表物化视图
- 查询时如何找到最佳的 物化视图
- 如何根据最佳的物化视图改写查询计划
- 如何在查询性能,导入速度,存储成本 3者之间权衡:Googel Masa的继任者 ———— Google Napa 在这一点给出了很好的答案
那么什么时候物化视图技术是必须的呢?
答案是当你要处理的数据量极大(千亿,万亿),或者数据量集群规模很小(几台,几十台),或查询计算量又很大(几十张表Join,精确去重),而且查询时延要求低,基于 CPU 的现场计算几乎无法满足需求的时候,可以使用物化视图 (我想这也是 Google Masa 和 Google Napa 都重度依赖物化视图的原因)。如果本身数据量不大或者集群资源充足或者查询不是特别复杂,可以考虑直接依靠现场计算 (我想这也是全球 90% 以上的中小企业不需要物化视图的原因)。
1.2 预聚合
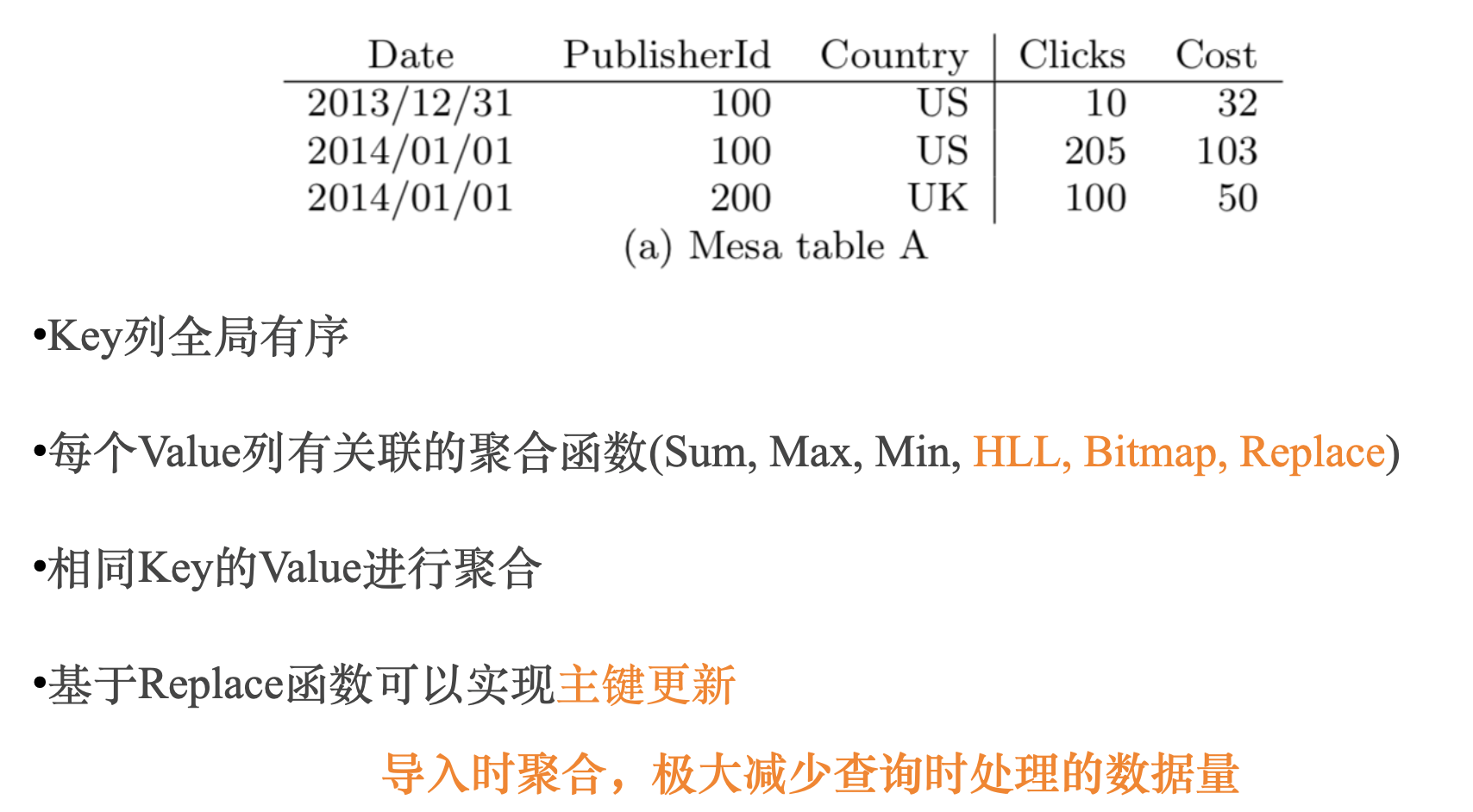
OLAP 系统中都会区分维度列和指标列,所谓预聚合,就是在导入时,把相同维度列的数据从多行聚合成一行,维度列值不变,指标列根据关联的聚合函数进行聚合,这样原始1亿行数据,预聚合后可能只有几百万行,现场计算处理几百万数据显然会比处理1一行数据快很多
预聚合也是 OLAP 数据库的常见加速手段,比如:
- StarRocks 中的聚合模型
- Apache Druid 中的聚合模型
1.3 索引
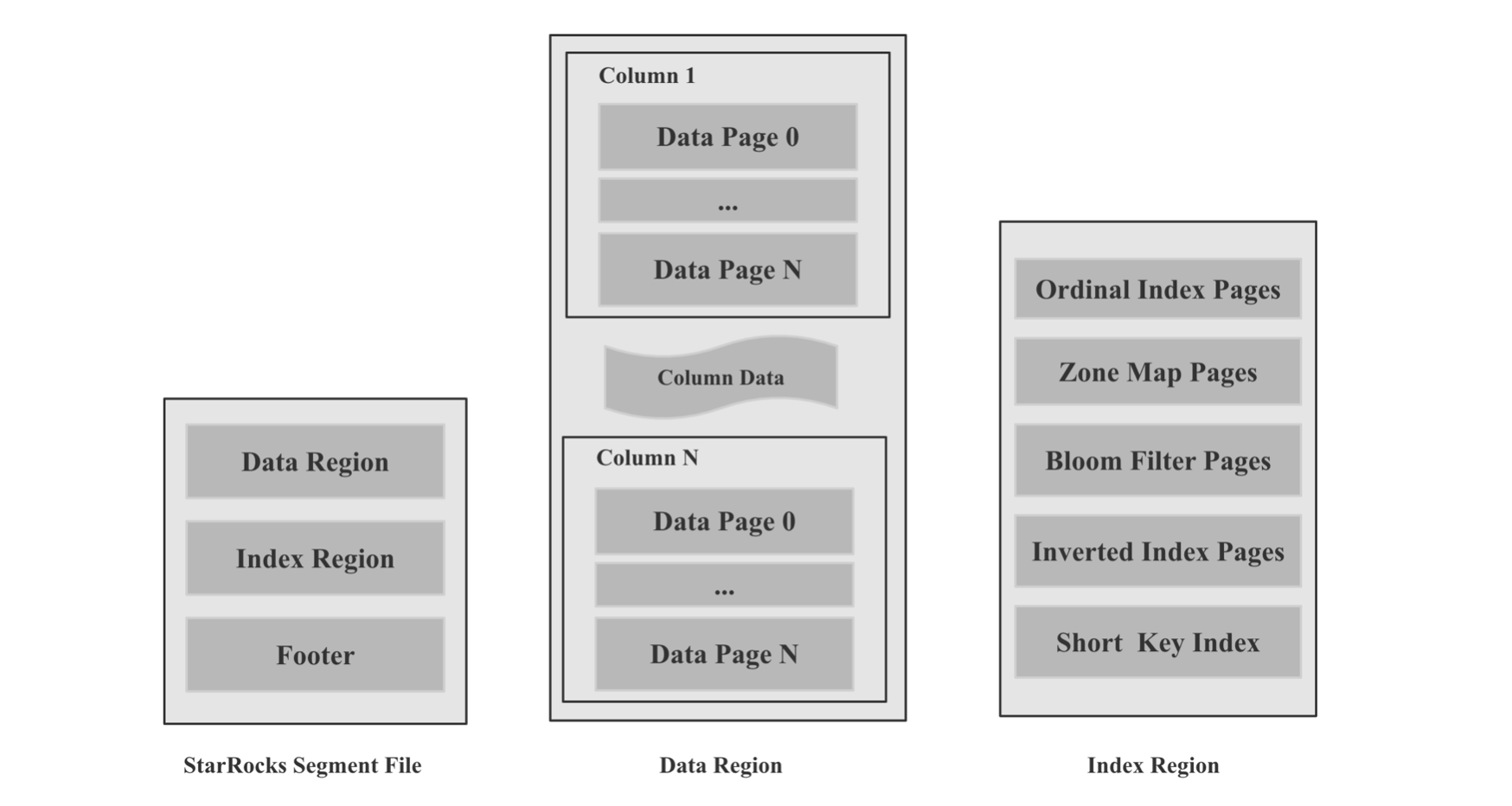
在 数据库从0到0.1 (一): LSM-Tree VS B-Tree 一文中,我解释了索引的概念,所谓索引,就是原始数据之外的元数据或者数据结构,用来加速查找原始数据中的某个值,或者某个值的偏移量。索引一般分为轻量级索引和重量级索引。 轻量级索引包括 ZoneMap 索引(Max, Min, Has null)等,前缀索引,重量级索引包括 SkipList 索引,B-Tree 家族 索引,Hash 索引,Bitmap 索引, Bloom Filter 索引等,索引的具体技术细节本文不展开讨论,索引的难点有以下几点:
- 数据库如何根据不同的数据规模,数据类型,数据基数自动选择构建不同类型的索引
- 一次查询可以使用多种索引时,如何自适应的选择最佳的索引
- 写入速度,存储成本,查询性能 3者之间的权衡
总而言之,索引的意义是避免存储层读取大量无关的数据,进而加速查询,是数据库存储层必不可少的加速手段。
1.4 Cache
Cache 在计算机中无处不在,如果我们明确一个相同的查询之后会被多次查询到,我们就可以对第一次查询进行Cache。 Cache 可以在多个层次,比如操作系统本身的 Page Cache,数据库存储层针对文件或者 Page, Block 级别的 Cache,数据库计算层针对分区,Segment,结果集的 Cache。 Cache 的难点在于如何避免频繁换入换出,如何保证 Cache 的命中率,讨论 Cache 的文章很多,本文就不深入展开。
Load VS Compaction VS Query
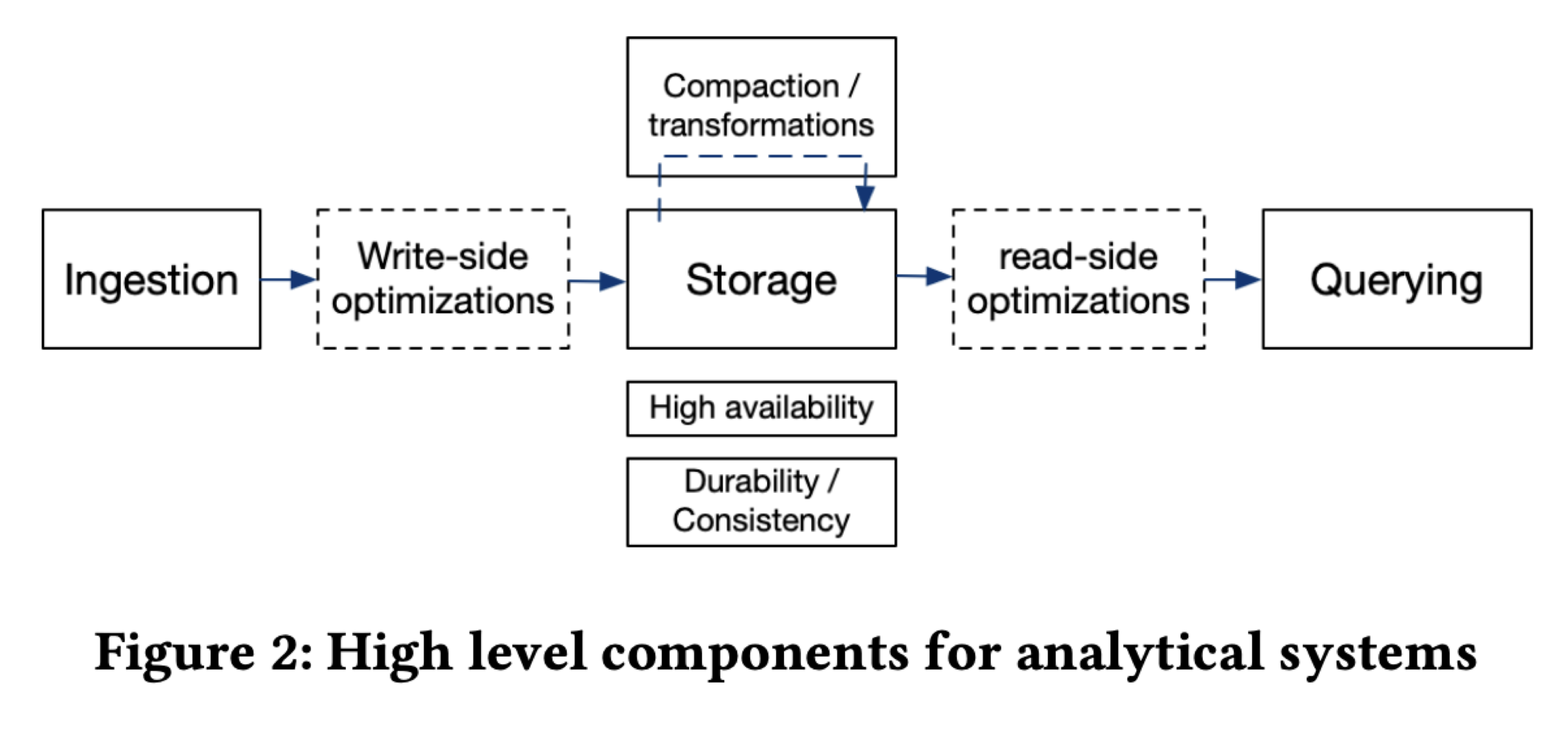
如上图所示,在数据库整个生命周期内,除了 Load 和 查询,大多数 OLAP 数据库还有 Compaction 的过程,很多在 Load 过程中可以做的优化,如果为了降低 Load 的延迟,我们可以考虑转移到 Compaction 的过程中去做,比如:
- 索引的构建:可以导入时只构建轻量级索引, Compaction 过程中构建重量级索引
- MV的构建
- 重新按照不同的 Sort Key 排序