从 Scale 视角进行优化
大约 2 分钟
现在的分析型数据库几乎都是分布式数据库,而我们知道分布式数据库最关键的就是 Scale 的能力,为了实现极致的性能,从 Scale 的视角来看 一个数据库必须拥有以下三方面的能力:
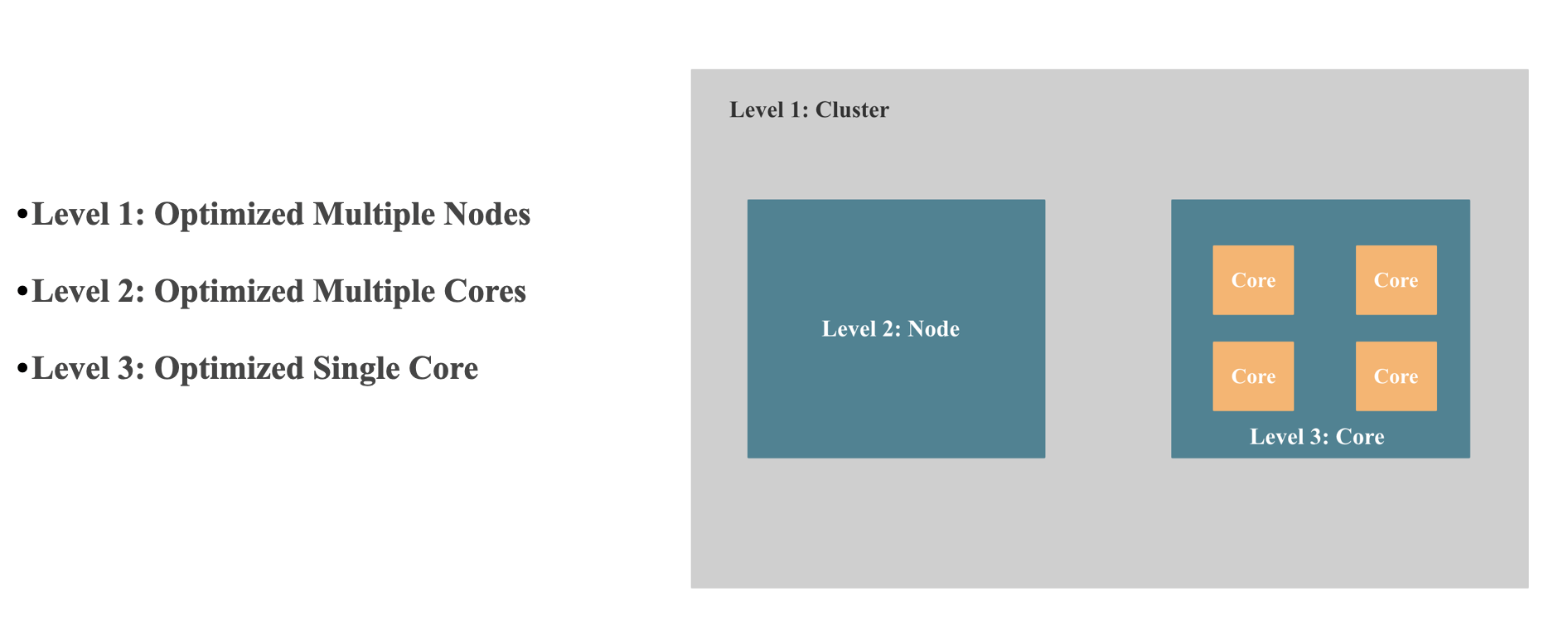
- 多机 Scale 的能力 或者说是 能充分调用整个集群资源的能力: 简单点说,就是查询性能可以随着机器数线性扩展。 多机 Scale 能力主要看 分布式执行框架是不是可以多机线性扩展,比如:StarRocks 的 MPP 分布式执行框架就是可以多机线性扩展的,Apache Kylin, Apache Druid, ClickHouse 的 Scatter-Gather 多机执行框架就是无法多机线性扩展的,具有单点瓶颈,没有 Shuffle 的能力,所以无法高效实现高基数聚合,大表Join 等需要 Shuffle的查询。
- 多核 Scale 的能力 或者说 能充分调用单机上多核的能力:简单点说,就是查询性能可以随着 CPU 核数近似线性扩展。 多核 Scale 能力主要看单机并行执行框架是不是可以多核线性扩展, 比如:StarRcoks 旧的并行框架线性扩展能力就比较差,StarRcoks 新的 Pipeline 并行框架多核线性扩展能力就很强,还有不同算子并行算法的实现方式,Lock 的优化,NUMA 友好的设计,CPU 亲和性调度, False sharing, 异步执行等。
- 单核 CPU 性能挖掘到极致:为了将 CPU 性能挖掘到极致,我们就需要减少查询执行使用的 CPU 指令数 和 CPI,尽可能触发 CPU SIMD 指令优化,减少 CPU Cache Miss, 一般有向量化执行和查询编译两种手段,StarRocks, ClickHouse,Snowflake 等系统采用了 向量化执行的手段, SingleStore, Hyper, NoisePage 等系统采用了查询编译的手段。 向量化执行细节会在后文提到, 查询编译之后会专门写一篇文章介绍。
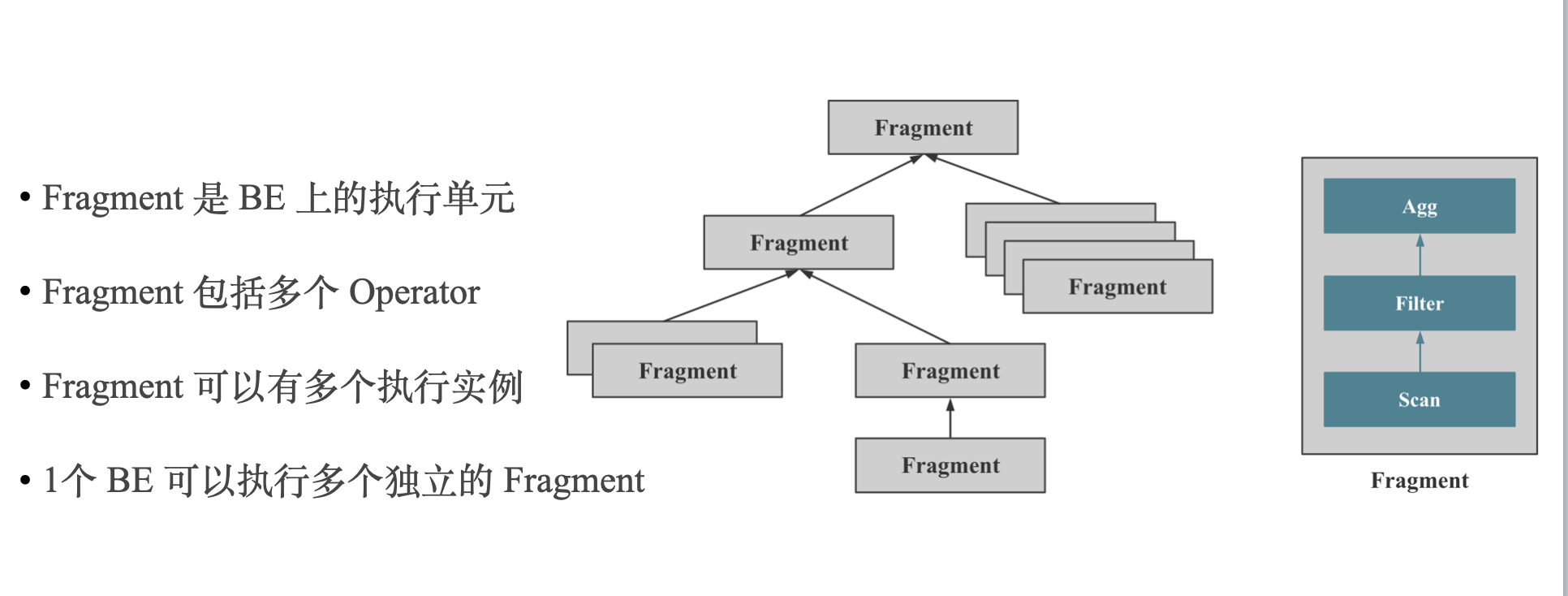
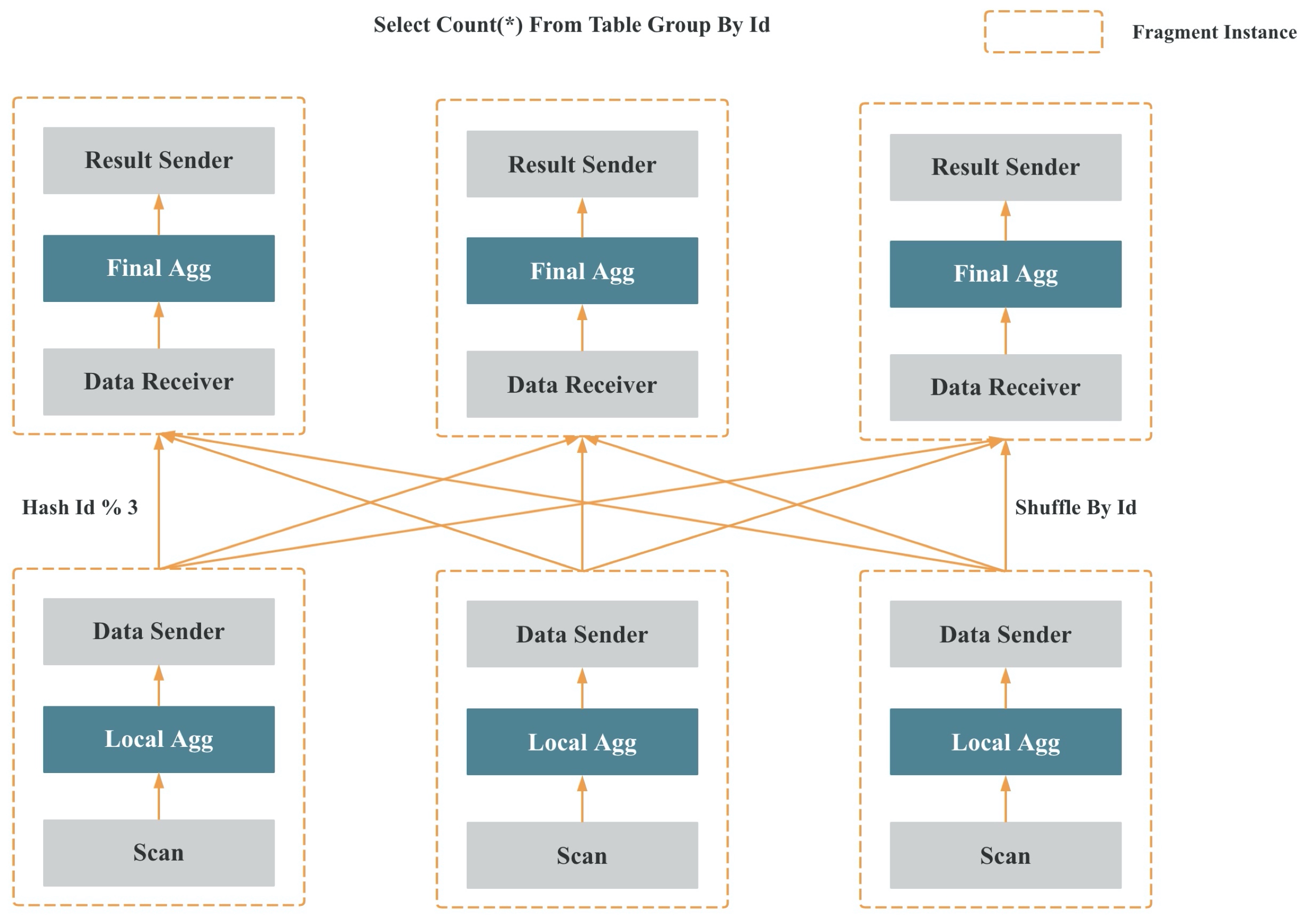
上两张图是 StarRocks MPP 分布式执行框架的示意。
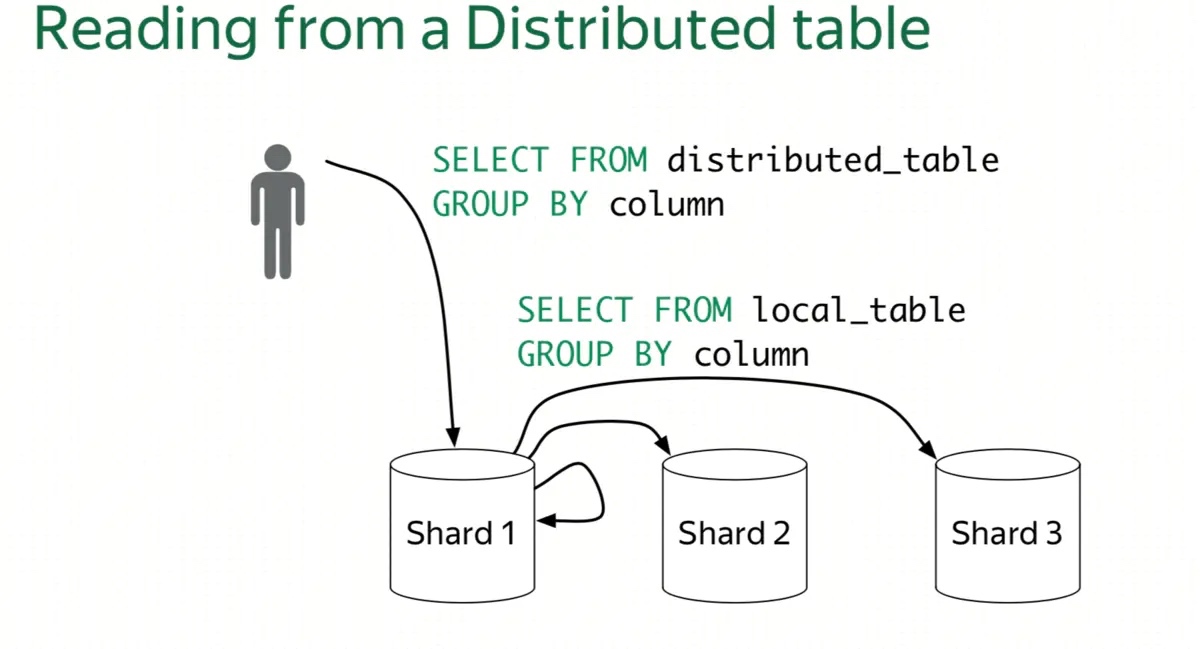
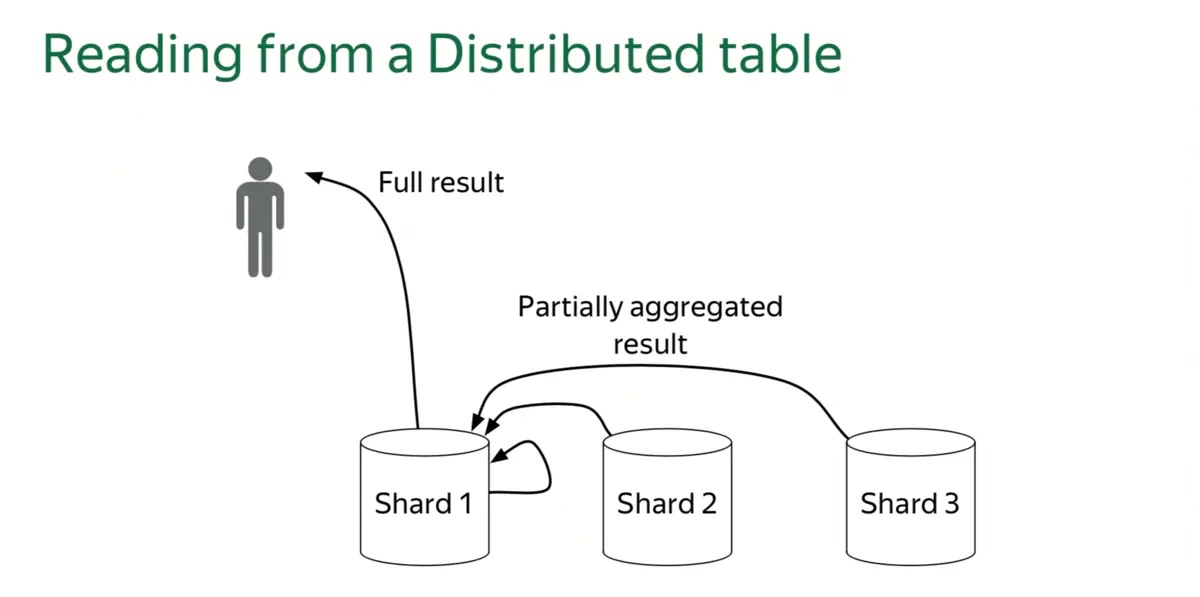
上两张图是 ClickHouse Scatter-Gather 执行框架的示意。
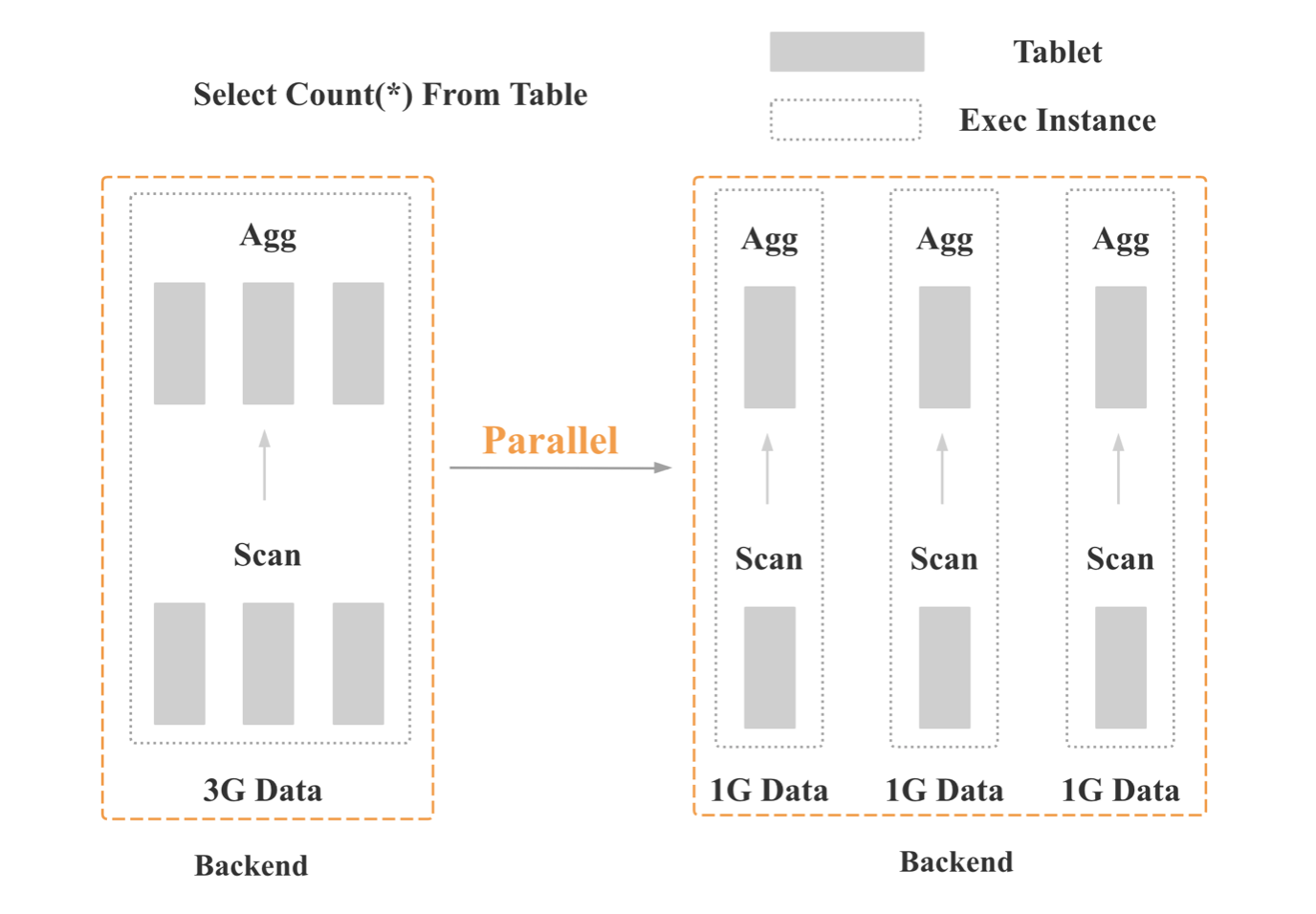
上图是 StarRocks 旧版并行框架的示意,核心是数据并行。
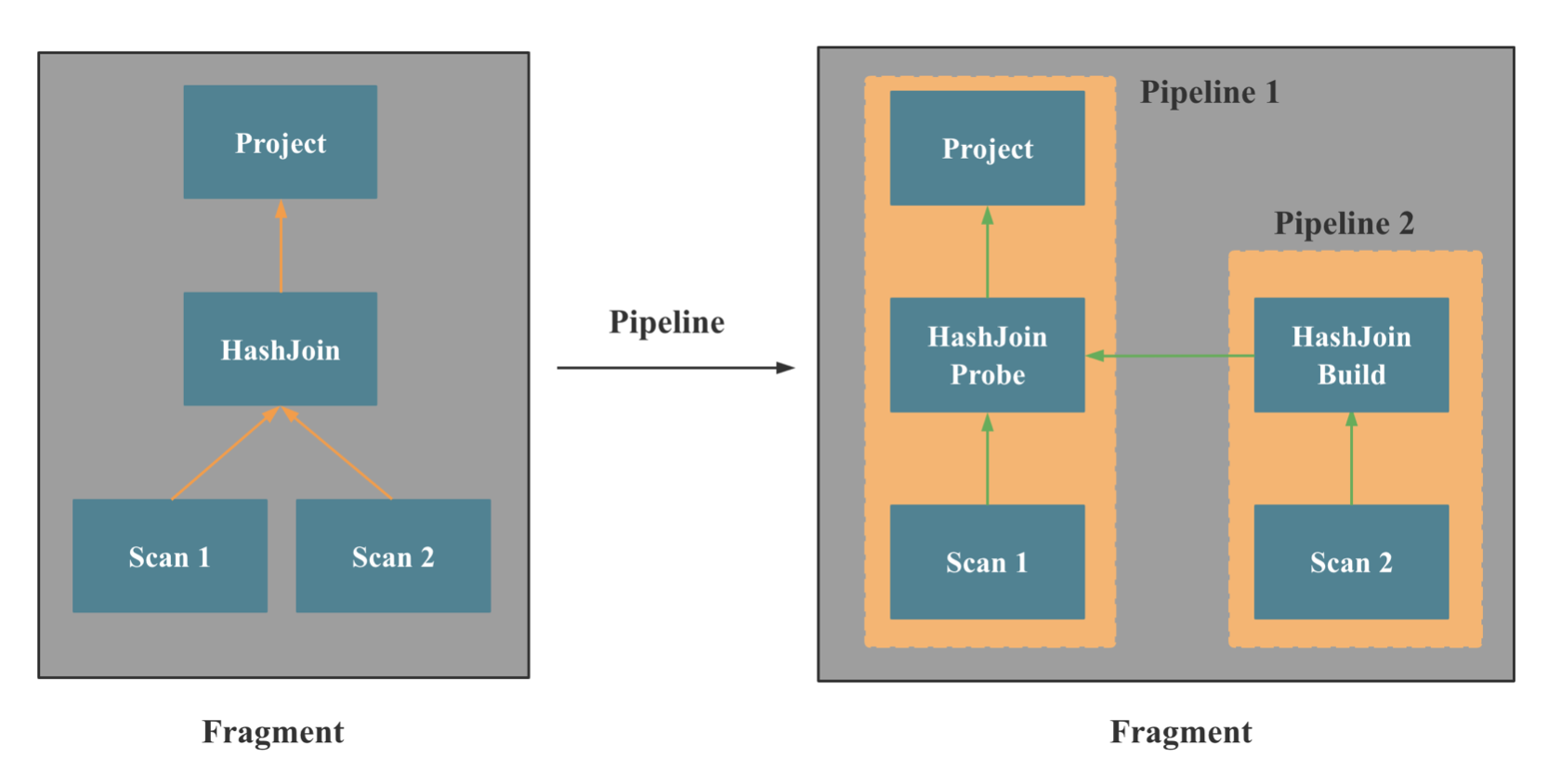
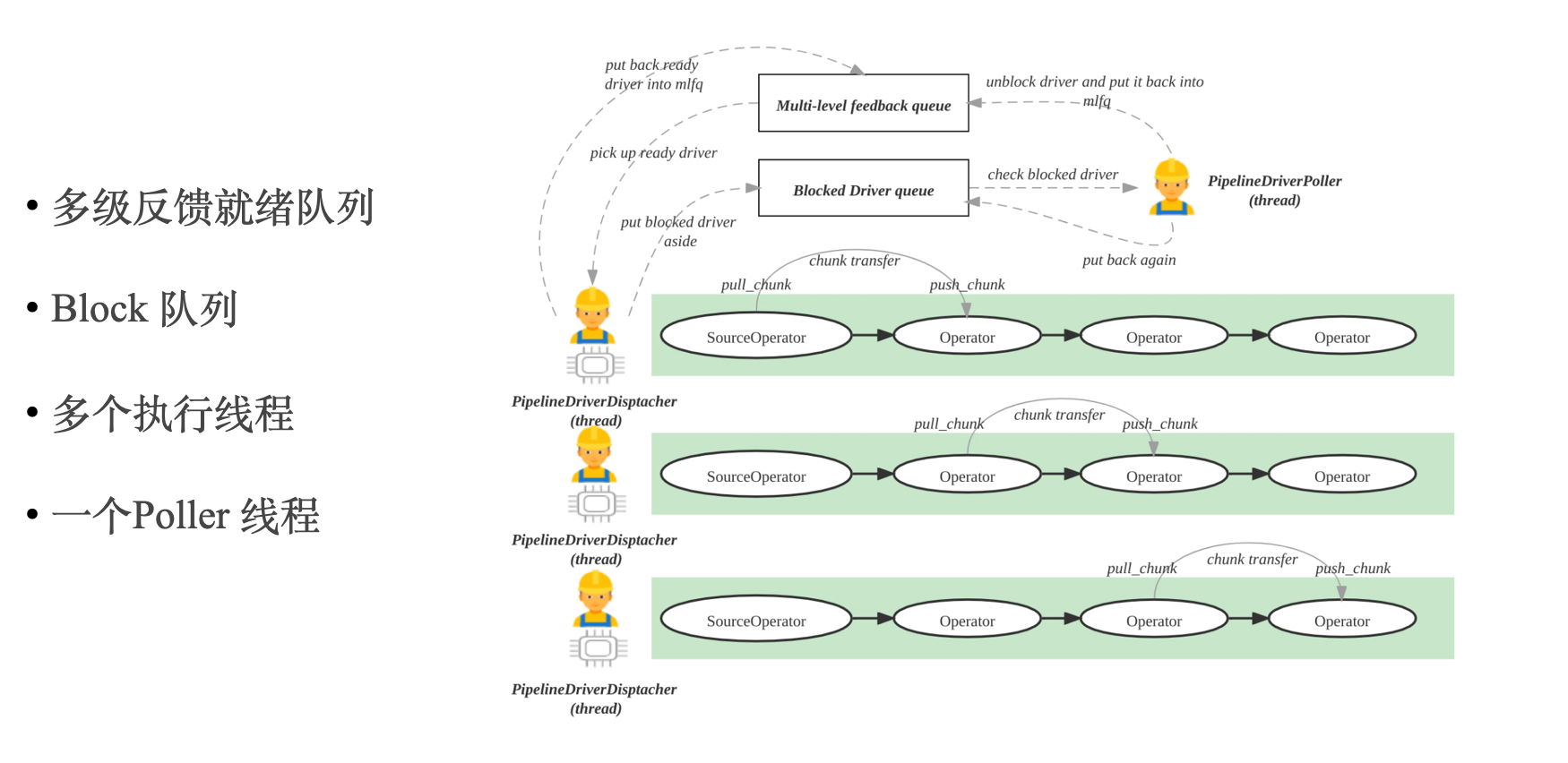
上两张图是 StarRocks Pipeline 并行执行框架的示意,核心是在 Fragment 和 Operator 之间引入了 Pipeline 的概念,将内核态多线程调度变成用户态协程调度。