算法和数据结构
大约 1 分钟
算法
反向二分搜索
https://www.vldb.org/pvldb/vol15/p3472-yu.pdf
In Filter
In 的数据量少时,可以用 Array 代替 HashSet
数据结构
Vector
https://github.com/facebook/folly/blob/main/folly/small_vector.h
聚合
两阶段 Streaming 聚合
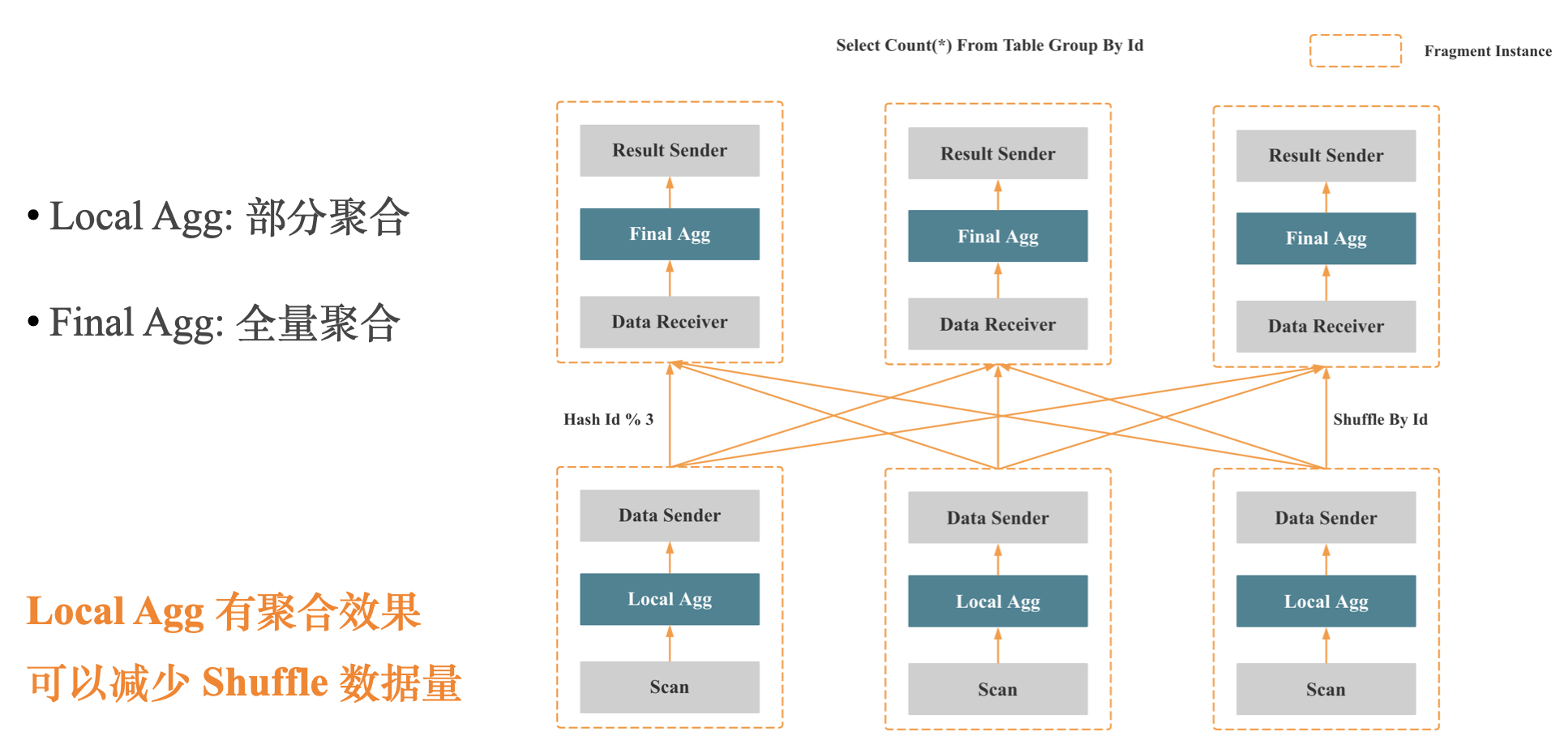
上图是分布式两阶段聚合,第一个阶段聚合数据都需要进 Hash 表,适合 Group By 列是中低基数的场景
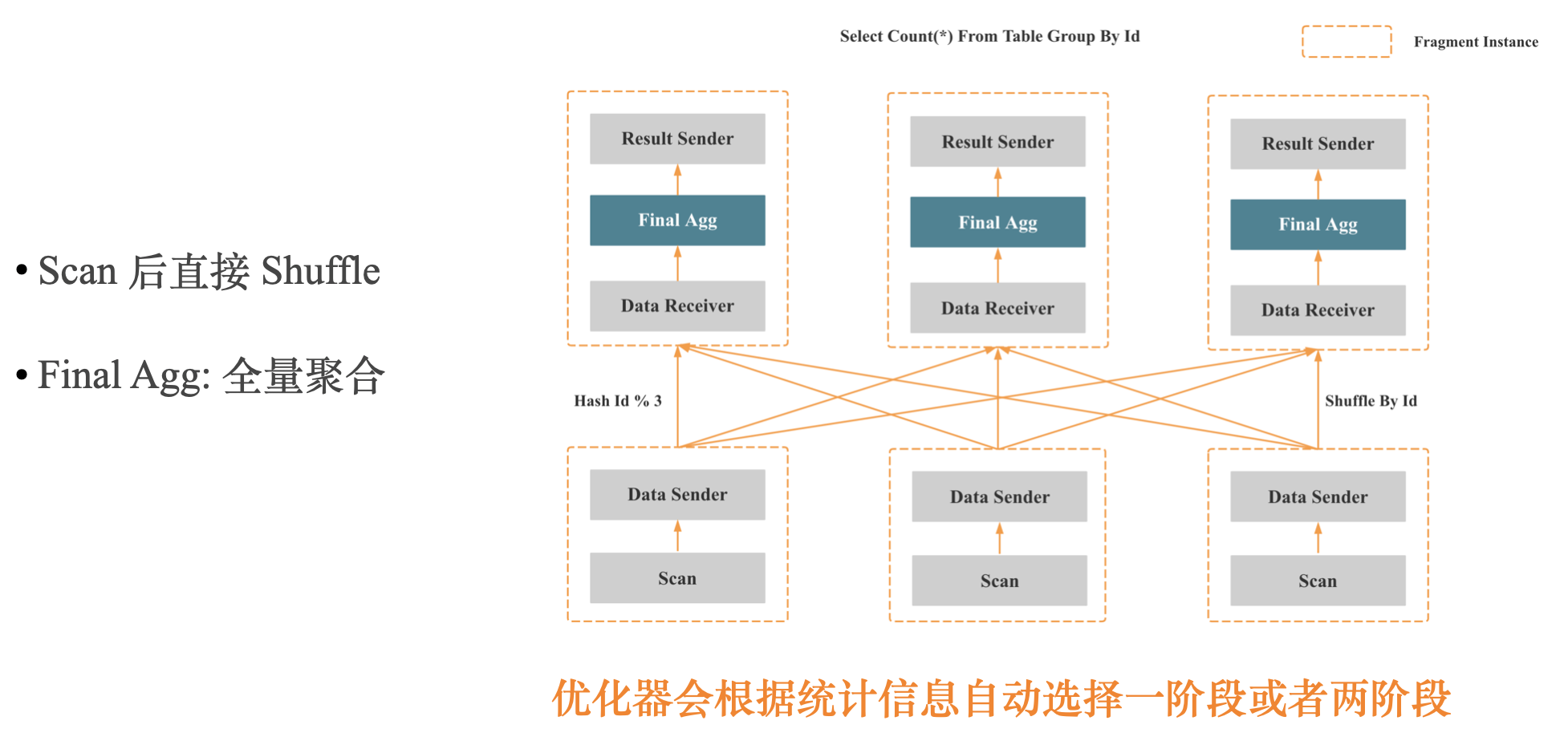
上图是分布式一阶段聚合,Scan的数据直接进行 Shuffle,只聚合一次,适合 Group By 列是高基数的场景
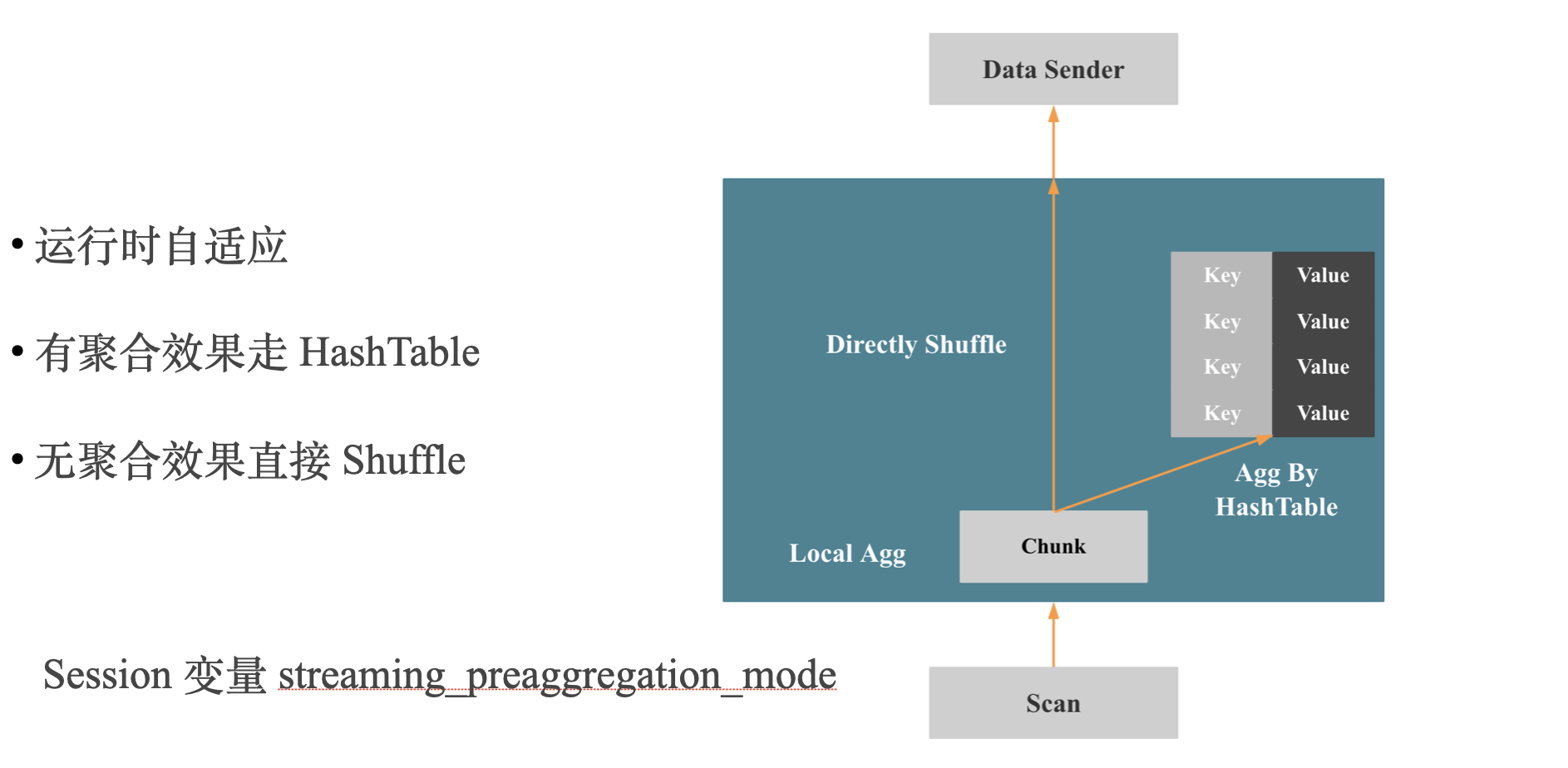
上图是分布式两阶段聚合 的自适应 Streaming 版本,第一阶段聚合会进行自适应,会先构建一个小的 Hash 表,如何聚合效果不好,后面的数据就不再访问 Hash 表,直接进行 Shuffle