SIMD
大约 2 分钟
注意事项
- AVX-512 is not always faster than AVX2. 原因是一些 CPU 可能会降频,还有编译器会 prefer 256-bit SIMD operations
- 内存对齐:直接调用 SIMD 指令编程时需要注意内存对齐
SIMD 基础知识
What SIMD
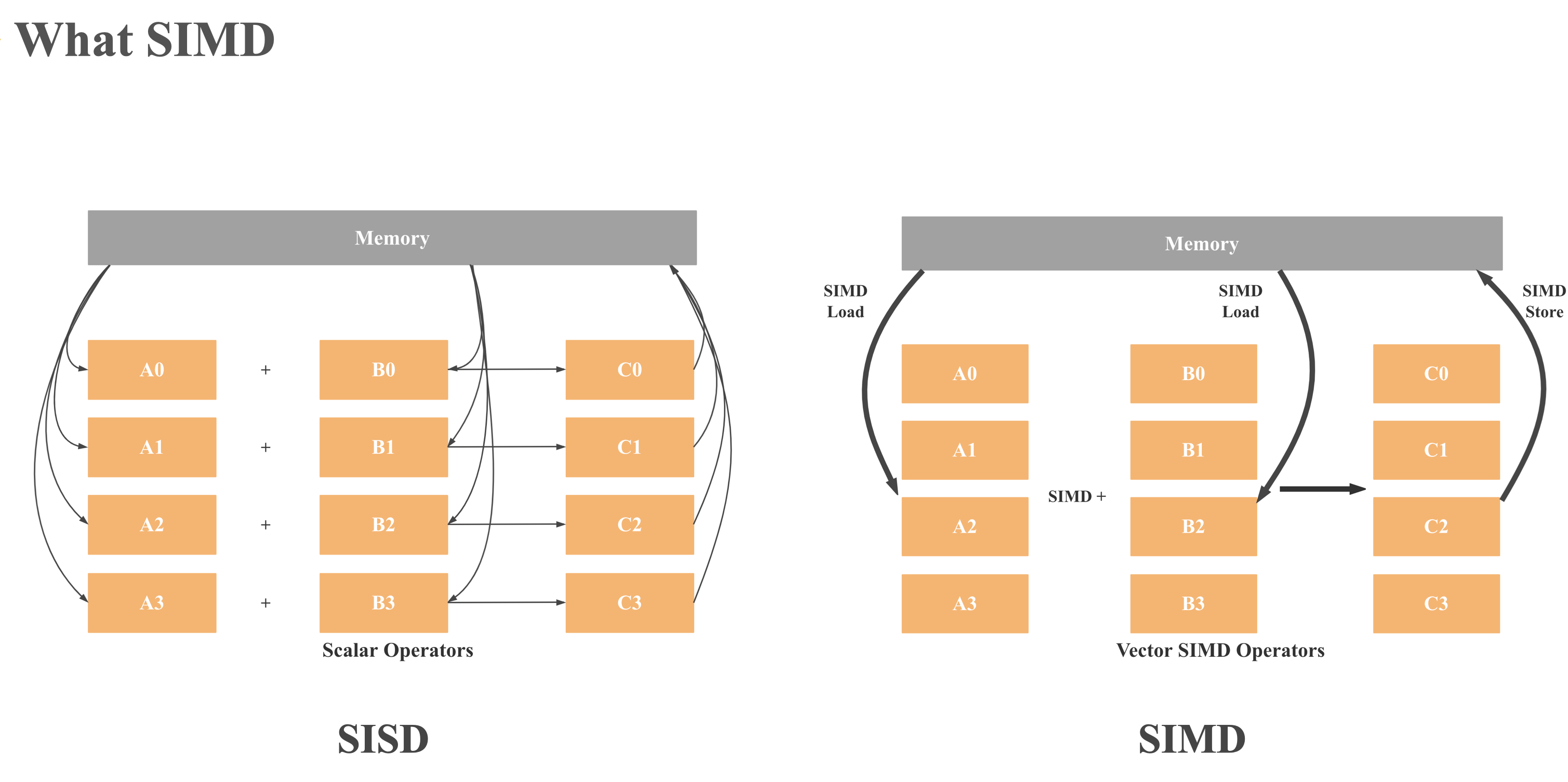
为什么向量化可以提升性能
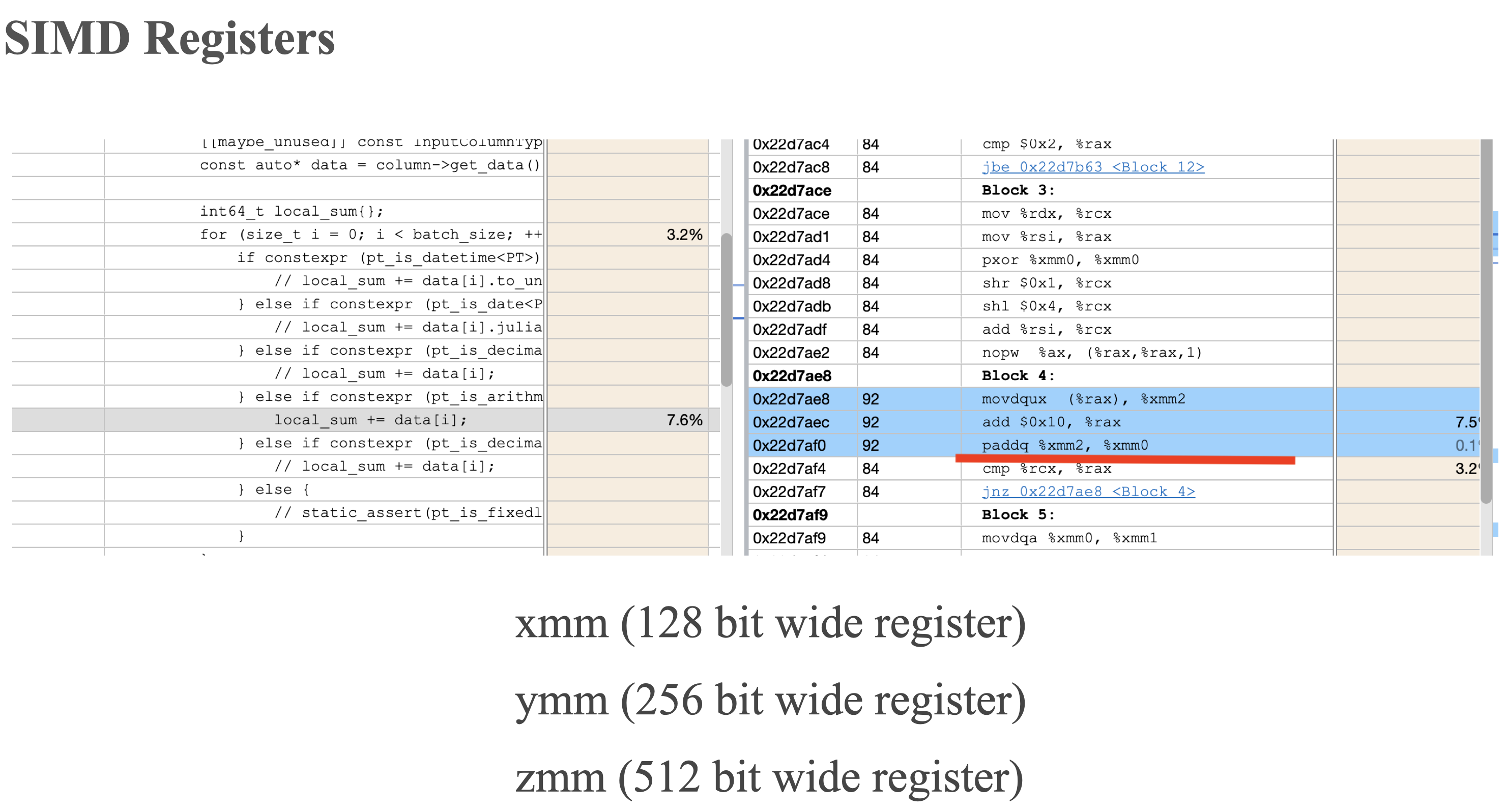
SIMD Registers
Many Ways to Vectorize
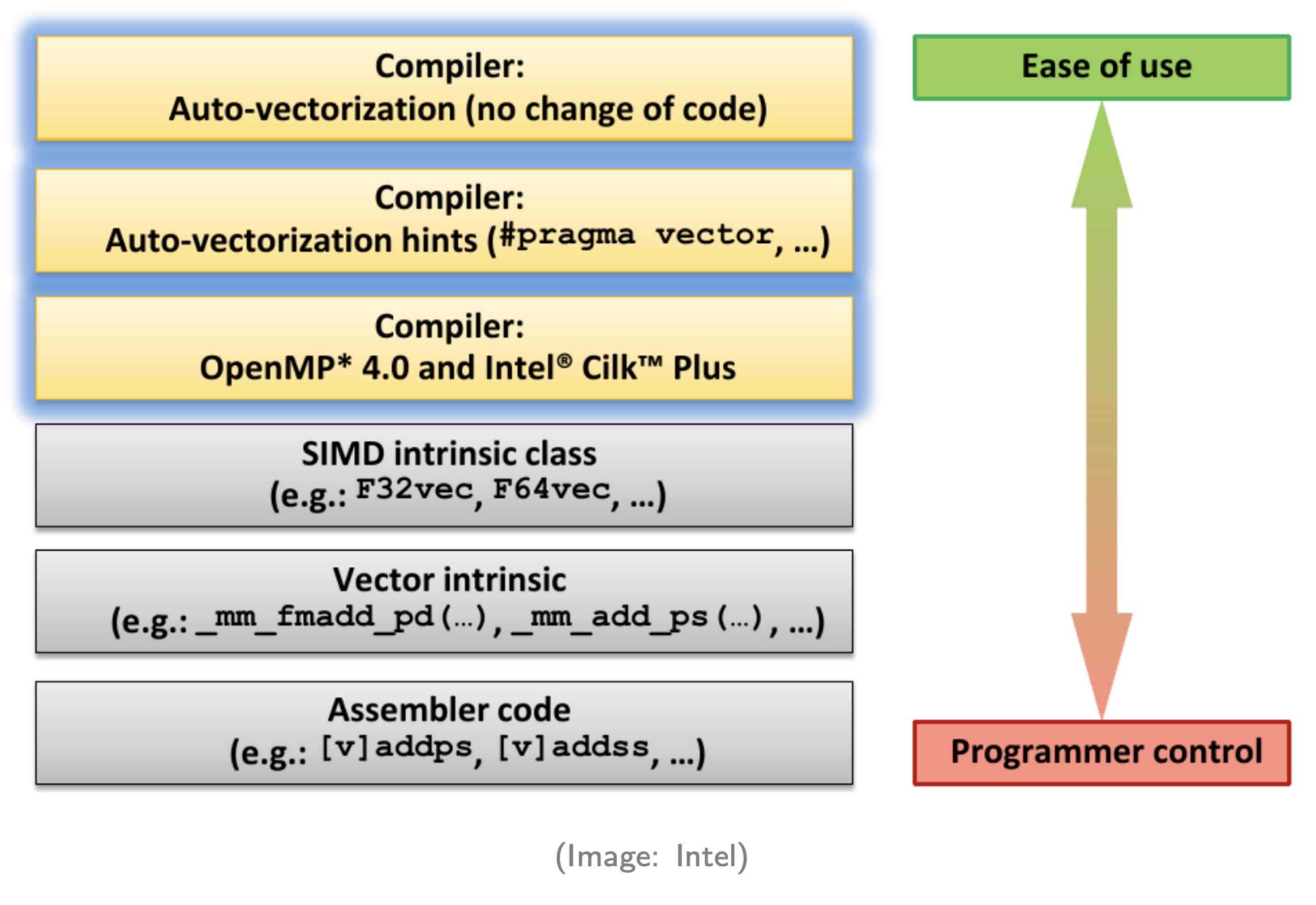
Compile Auto Vectorize
- Countable loop
- Function call should be inline or simple math function
- No data dependencies
- No complex conditions
Compile Hint Vectorize: Restrict
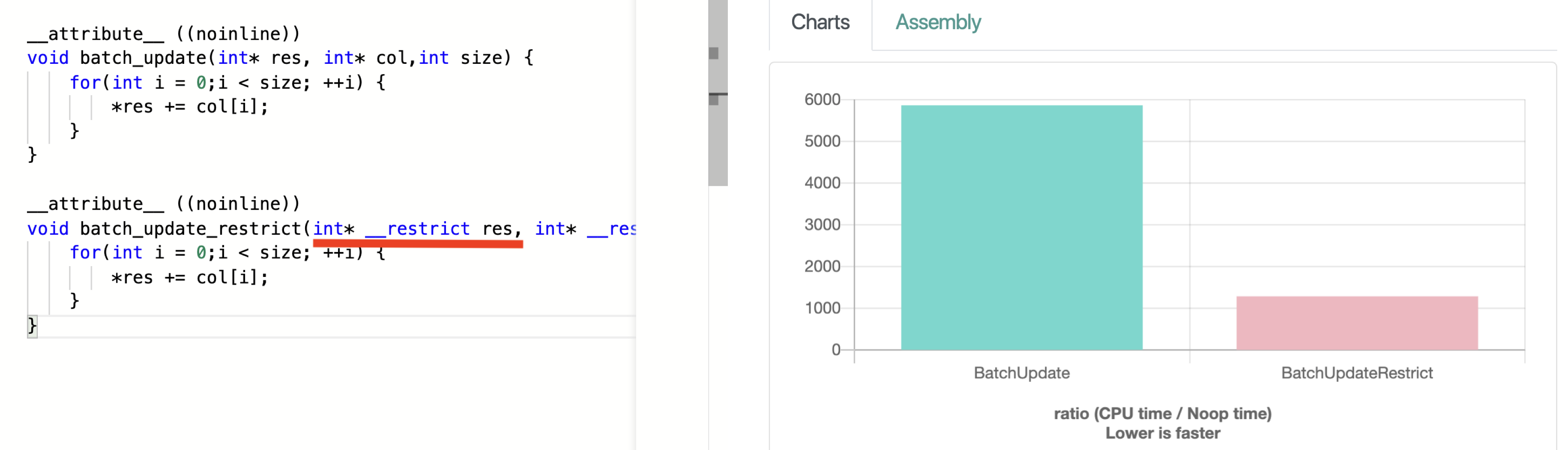
Restrict Tells The Compile The Arrays In Distinct Locations In Memory
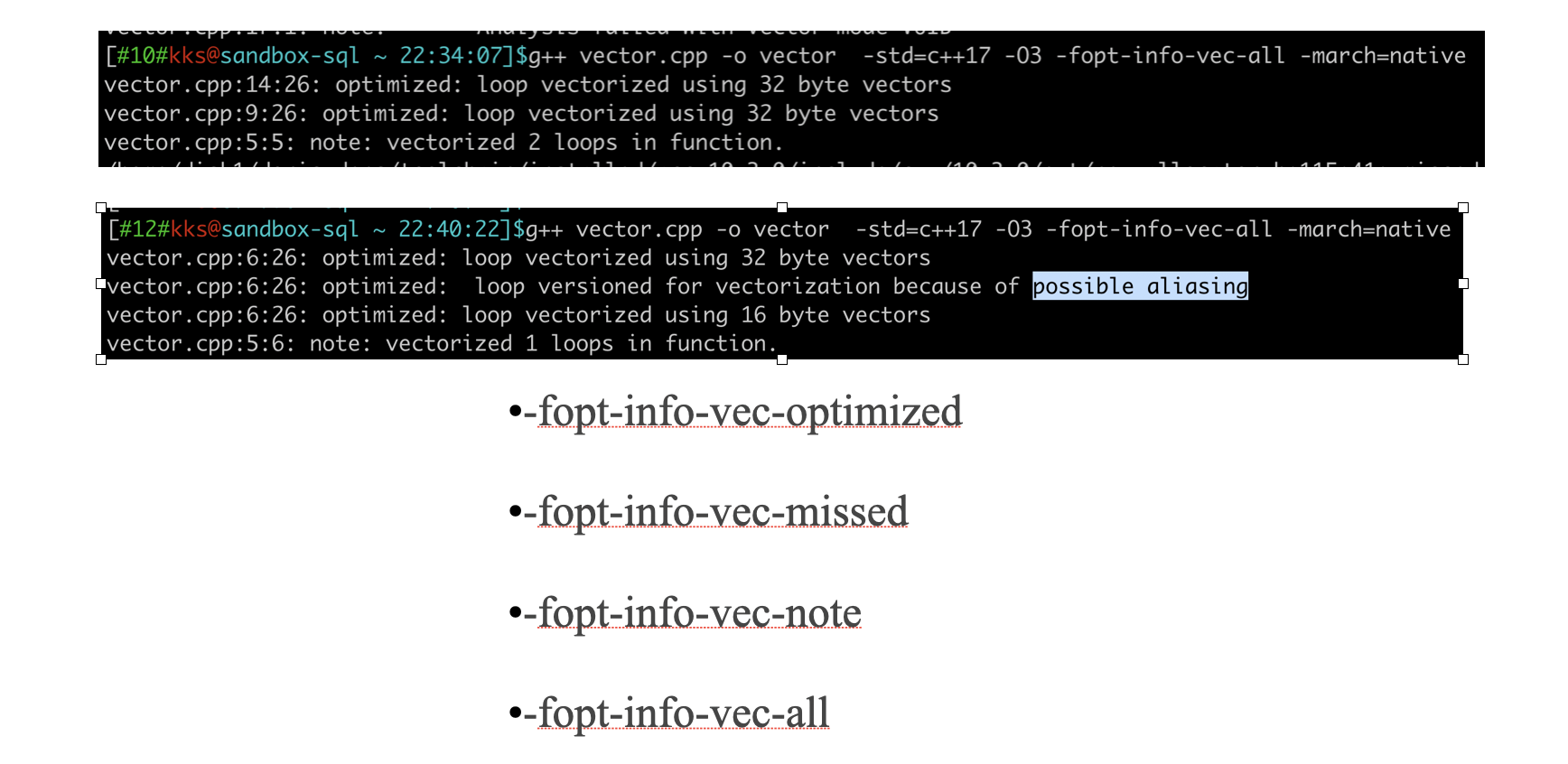
How to Ensure SIMD Instructions Used

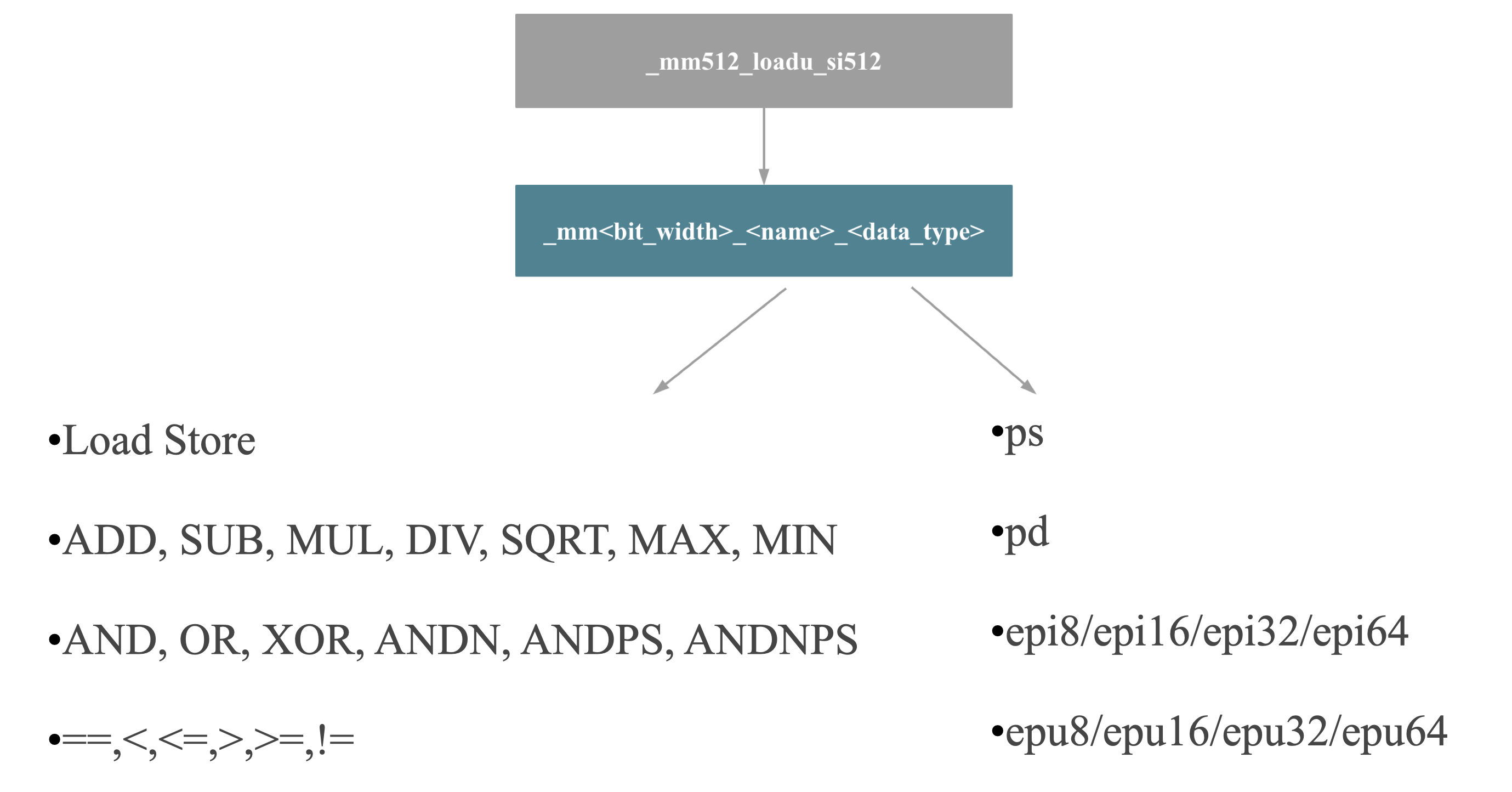
Vector Intrinsics
https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html

SIMD 优化案例
SIMD text parsing
SIMD time stamps parsing
Parsing time stamps faster with SIMD instructions
SIMD data filtering
SIMD string operations
SIMD json
SIMD join runtime filter
SIMD hash table probe
There are three opportunities to apply SIMD for the hash tables: hash computation and read or write values into the table.
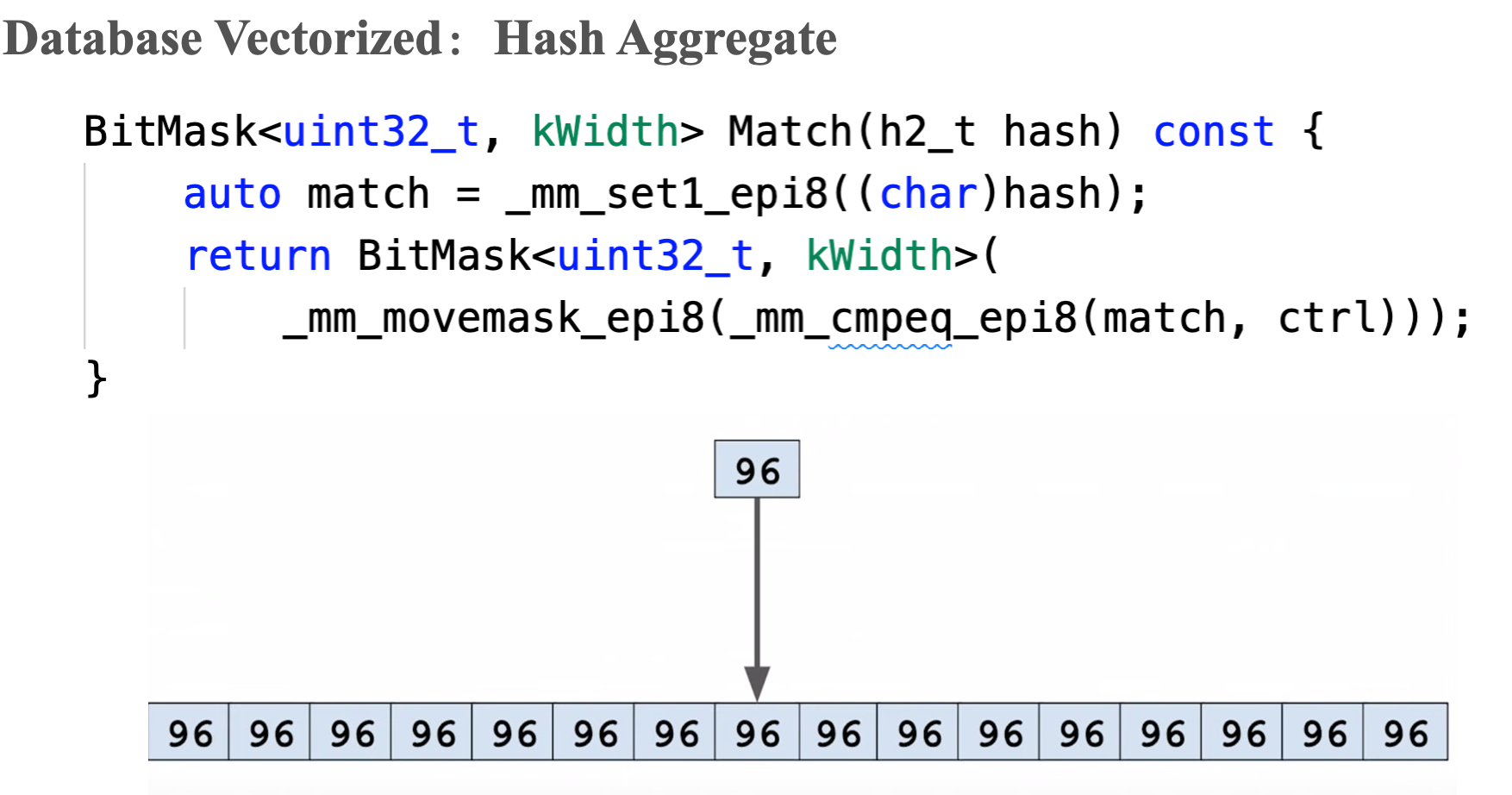

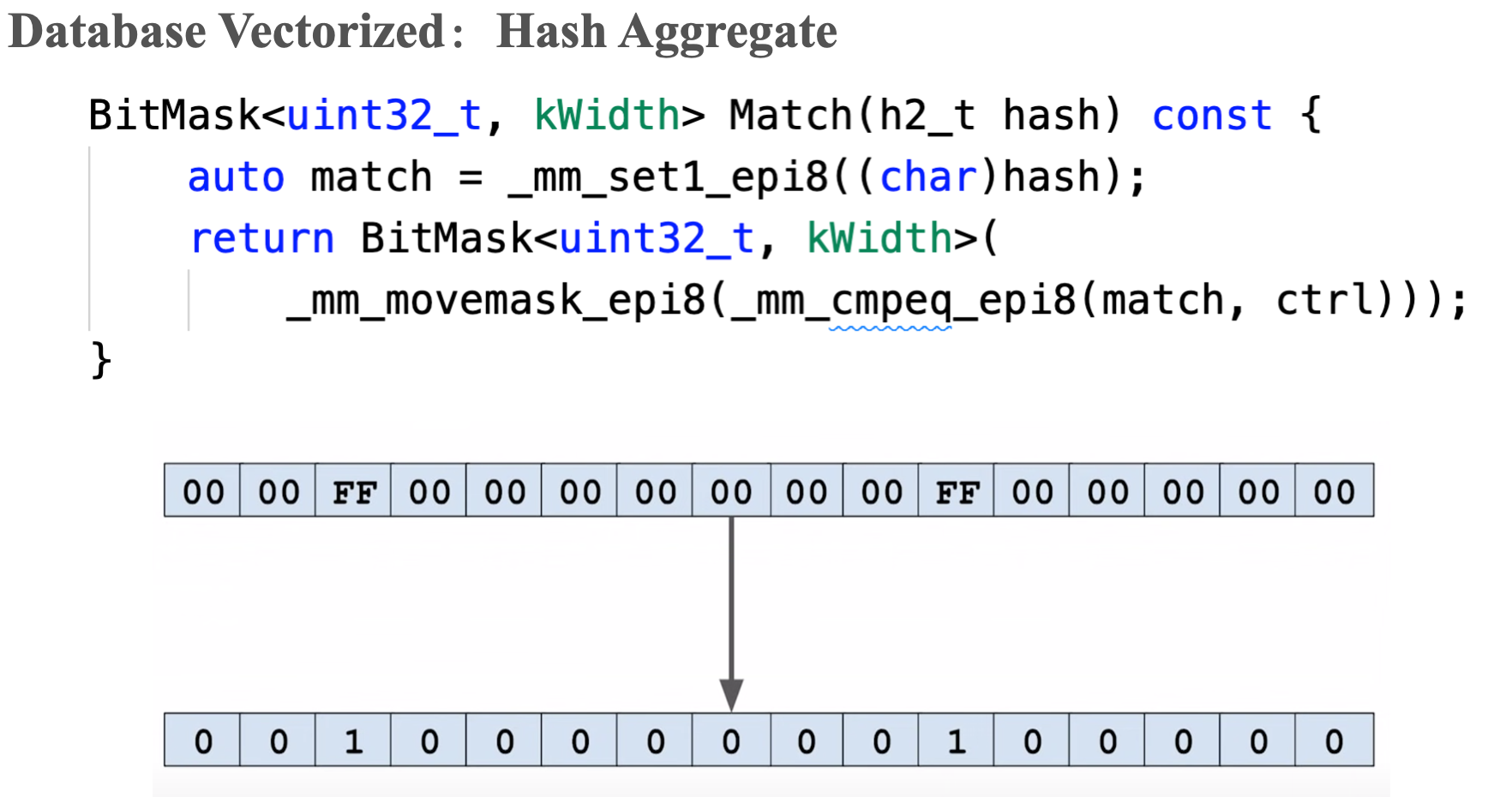

SIMD Join

SIMD memcpy
SIMD memcmp
SIMD memequal
SIMD case when
SIMD Gather
往往内存会成为瓶颈,导致 simd gather 加速不明显。
SIMD branchless
核心思想是每个分支都计算,然后利用 mask 选择不同分支的结果
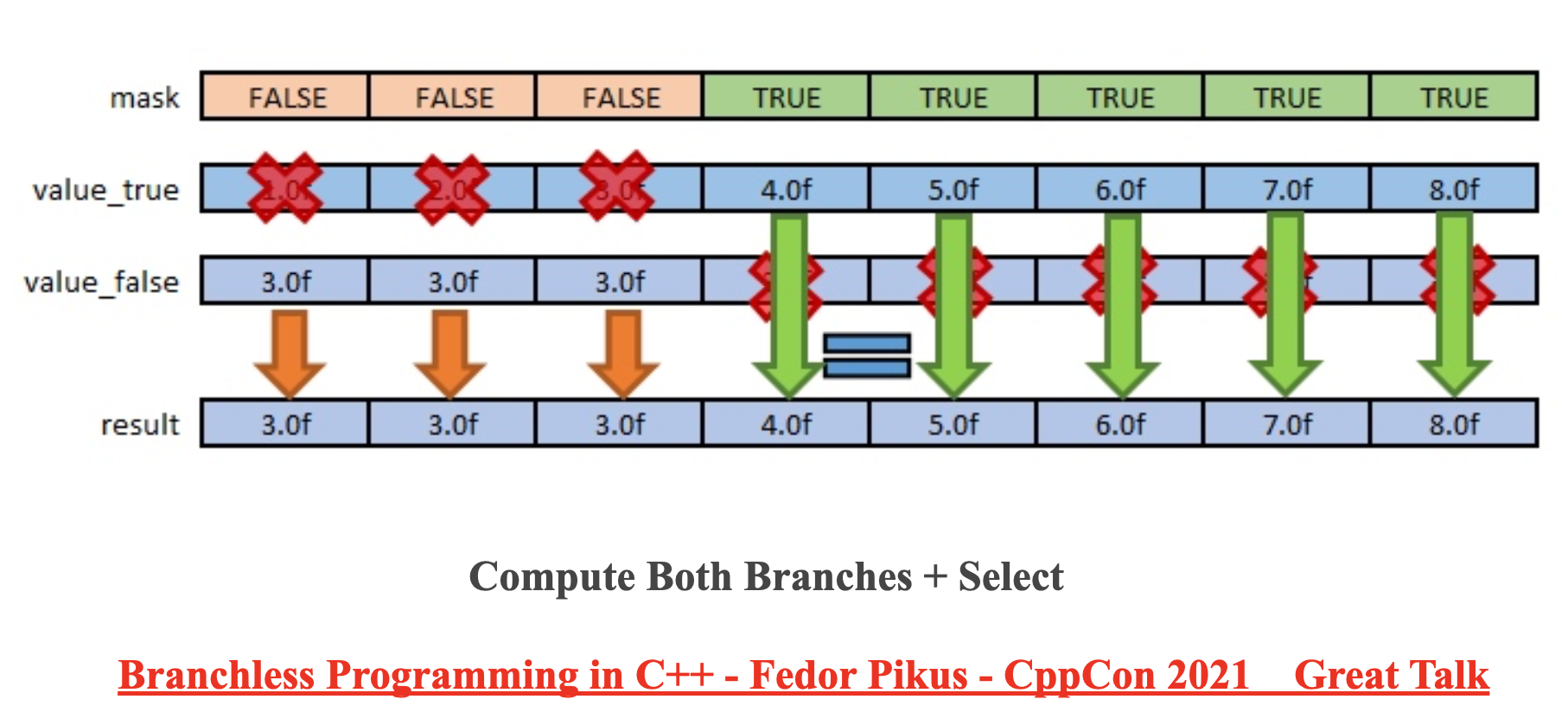
https://www.youtube.com/watch?v=g-WPhYREFjk
SIMD filter

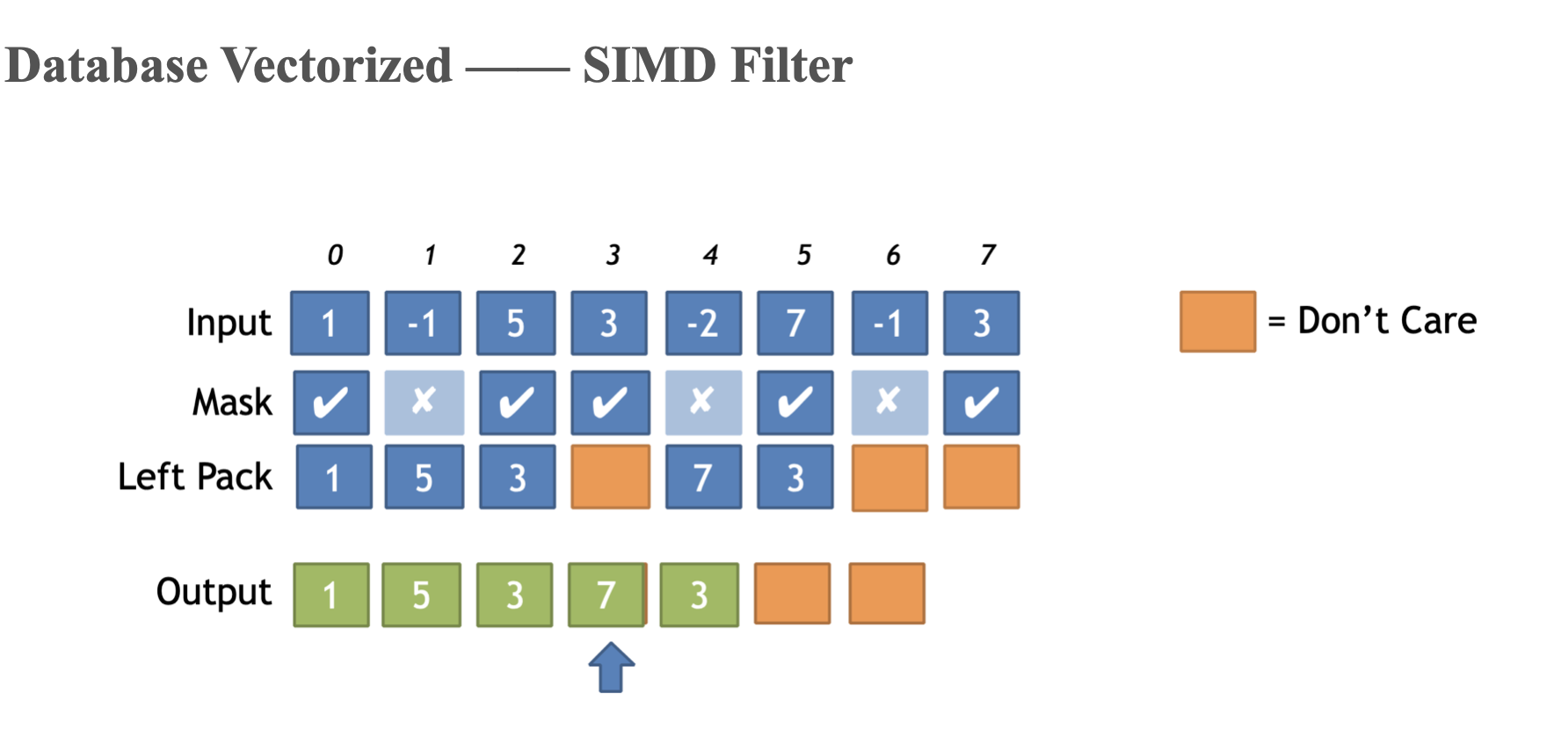
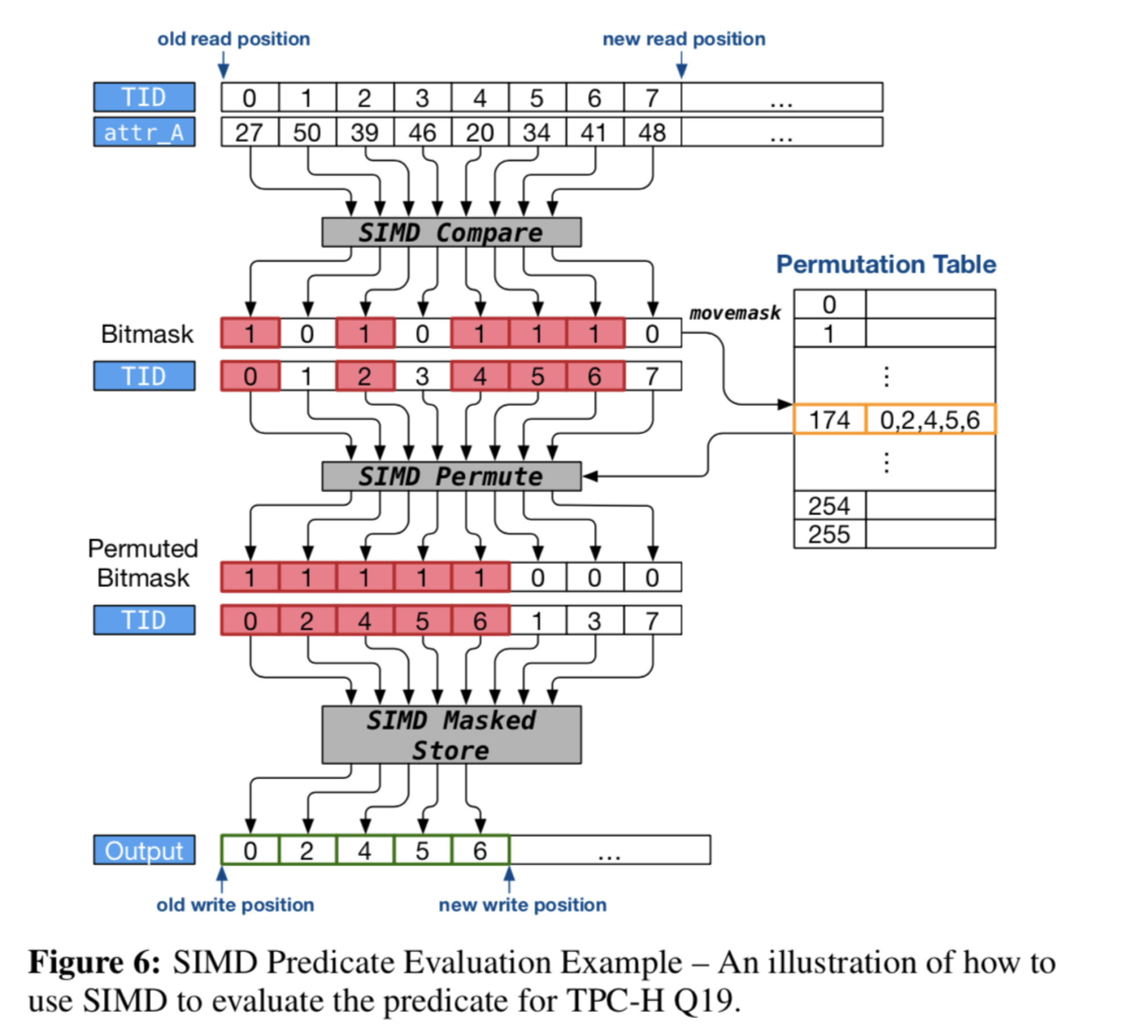
Starrocks optimize filter_range when avx512f available
SIMD aggregate
SIMD string to integer parser
SIMD std::find & memchr
SIMD std::find and memchr Optimizations
SIMD bitshuffle
Dynamic bit shuffle using SIMD AVX-512
SIMD ascii Substring

SIMD is sorted 判断
标量代码:
bool is_sorted(const int32_t* input, size_t n) {
if (n < 2) {
return true;
}
for (size_t i=0; i < n - 1; i++) {
if (input[i] > input[i + 1])
return false;
}
return true;
}
avx512 代码:
bool is_sorted_avx512(int32_t* a, size_t n) {
const __m512i shuffle_pattern = _mm512_setr_epi32(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 15);
size_t i = 0;
while (i < n - 16) {
const __m512i curr = _mm512_loadu_si512(reinterpret_cast<const __m512i*>(a + i));
const __m512i next = _mm512_permutexvar_epi32(shuffle_pattern, curr);
const __mmask16 mask = _mm512_cmpgt_epi32_mask(curr, next);
if (mask != 0) {
return false;
}
i += 15;
}
for (/**/; i + 1 < n; i++) {
if (a[i] > a[i + 1])
return false;
}
return true;
}
如何更好地触发向量化
循环外提
https://github.com/StarRocks/starrocks/pull/14510
循环展开 Unrolled Loop
Why are unrolled loops faster?
SIMD 收益
- 当数据都在 CPU Cache 中时,SIMD 指令的收益最明显
- 当一次要处理的数据集超过 Cache 容量时,Cache Miss 和 内存访问就会成为最大的 Cost
- 所以当你已经按列处理,发现 SIMD 指令收益不明显时,就应该首先考虑是不是 Cache Miss 的原因
多平台多SIMD指令兼容
Automatic SIMD-instruction selection