查询优化器优化点
大约 3 分钟
Parser 优化
Nullable 优化
Null 和 Nullable 是数据库中比较容易出错的点, Null 相关的很多逻辑都需要特殊处理,比如 Join, 聚合等算子,一些函数,谓词,四则运算 和 逻辑运算等。 而在向量化执行中, Null 和 Nullable 对性能的影响也很大。
Nullable 对性能的影响主要是两点:
- null 需要特殊判断,可能会需要很多 if else , 导致一些地方不能向量化和分支预测错误
- null 的数据需要占一个 column 或者 bitmap,会有额外的存储和计算开销。
StarRocks 对 Nullable 的优化主要体现在下面几点:
- 优化器对 Nullable 熟悉进行判断,如果可以确定表达式的结果一定是 Non-nullable 的,就会告诉执行层这个信息,这样执行层处理时完全不需要考虑 Null。比如 StarRocks 的这个PR: https://github.com/StarRocks/starrocks/pull/15380/files 当确定 cast 一定可以成功,且输入是 Non-nullable 的column时,结果就一定是 Non-nullable 的
- 利用 has_null 标识进行快速短路,如果一个chunk 里面的数据都没有null,就走 Non-nullable 的处理逻辑,在很多算子和函数中可以看到大量这种优化
- 利用 SIMD 指令快速对 全是 null 和 全不是 null 的 case 进行处理,在 StarRocks 的nullable_aggregate.h 可以看到大量这种优化
- 在表达式计算中,对 null 的 数组和 data 的数组分别进行向量化处理。
元数据优化
In Memory MetaData
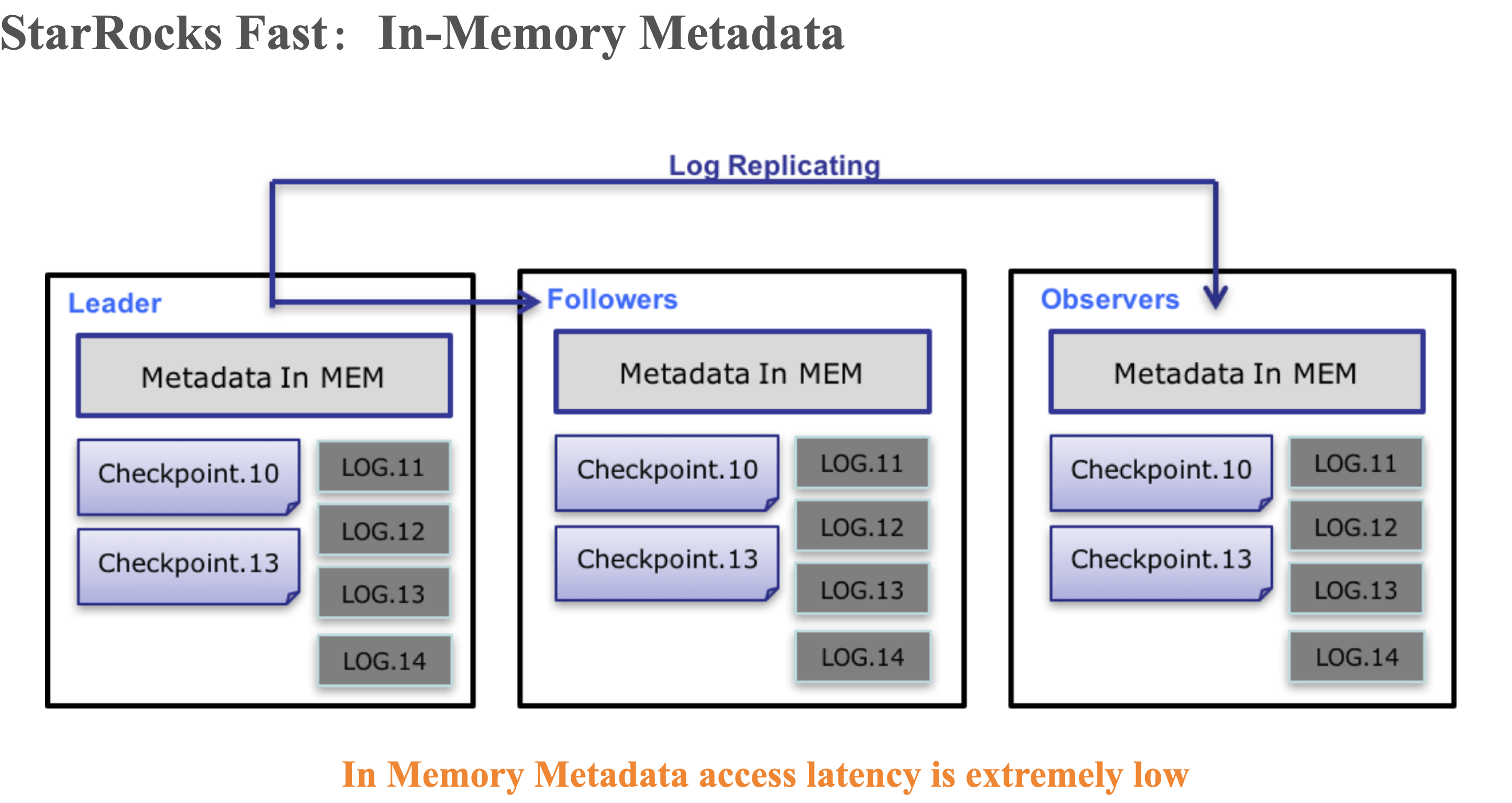
Memory Cache
利用元数据加速查询
- 全表 Count, Sum, Max, Min 的聚合查询可以直接从元数据查询 https://github.com/StarRocks/starrocks/pull/15542
- 利用元数据加速 统计信息计算的查询
- Small Materialized Aggregates: A Light Weight Index Structure for Data Warehousing https://www.vldb.org/conf/1998/p476.pdf
利用元数据改写查询

metadata-rewrite - Big Metadata: When Metadata is Big Data http://vldb.org/pvldb/vol14/p3083-edara.pdf
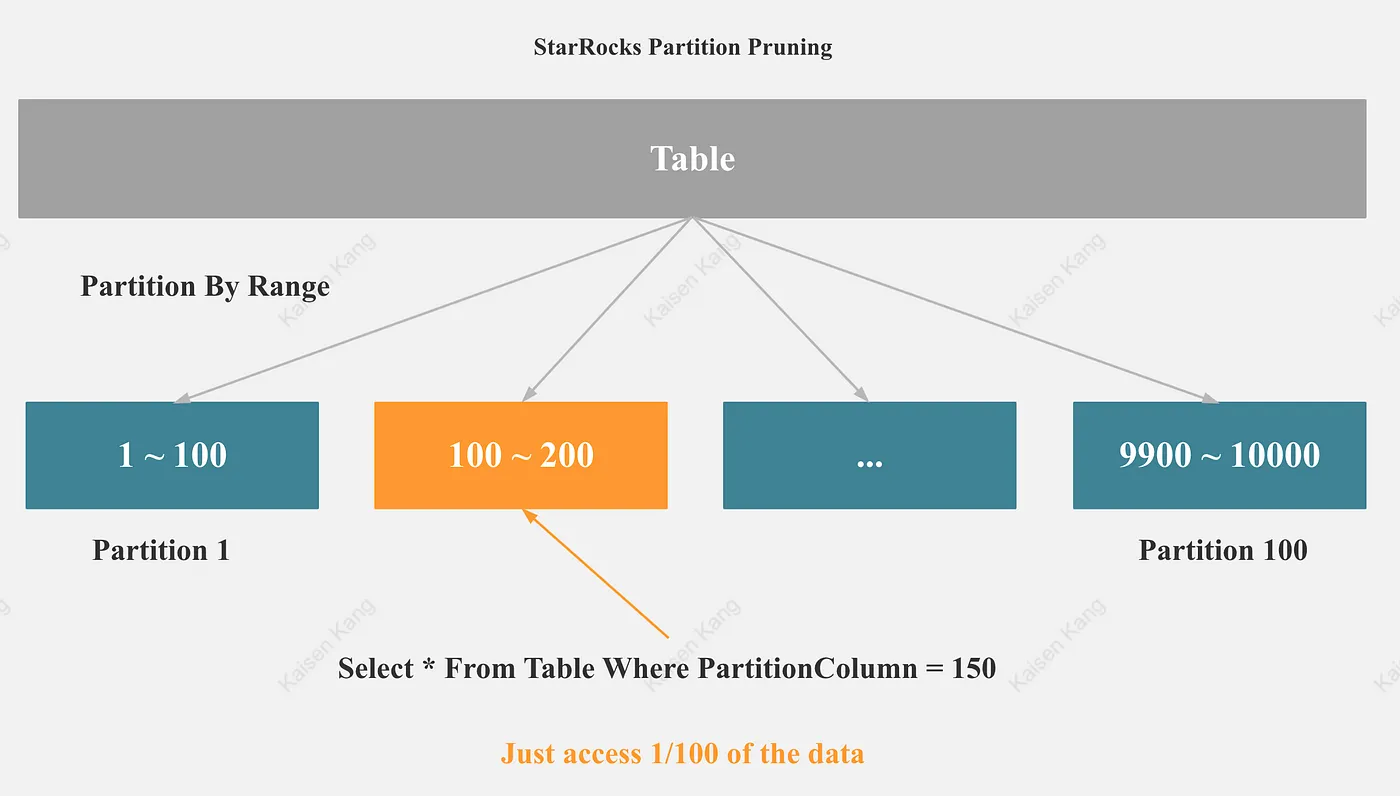
分区分桶裁剪
分区裁剪
分桶裁剪
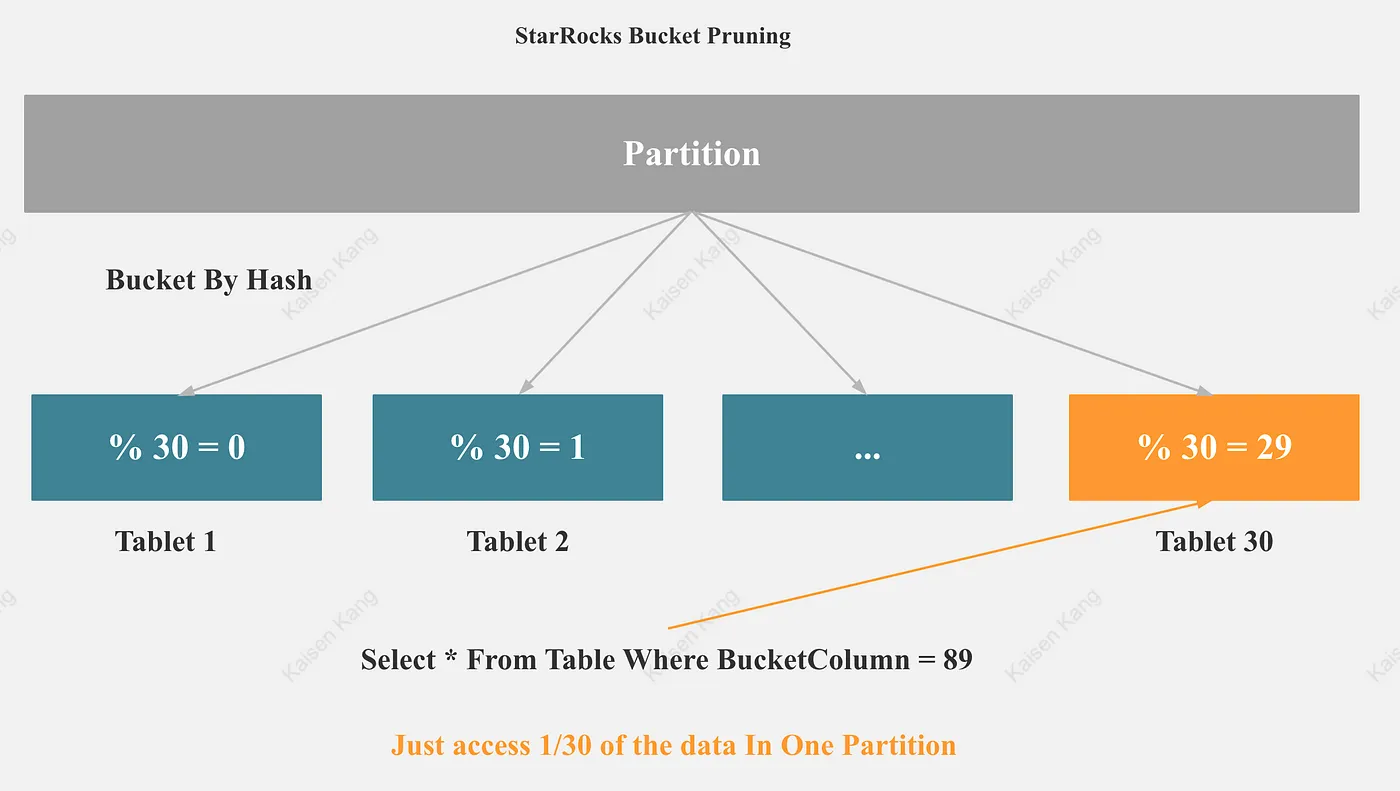
- 谓词触发分桶裁剪
- Limit 触发分桶裁剪
常见的RBO 优化
各种表达式的重写和化简
Cast 消除
谓词化简
公共谓词提取
列裁剪
Shuffle 列裁剪
确保任何多余的列不要参与网络传输
谓词下推
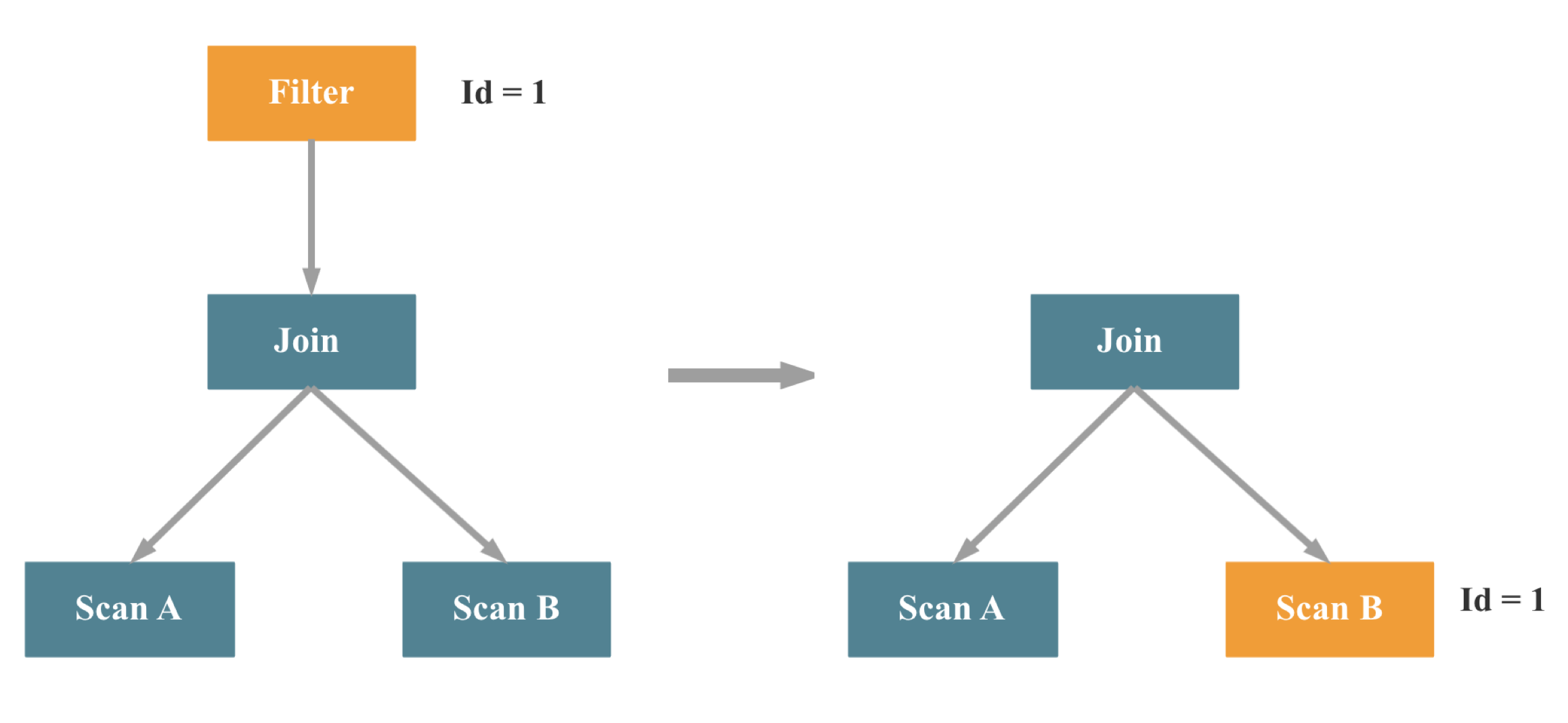
等价谓词推导(常量传播)
Outer Join 转 Inner Join
Limit Merge
Limit 下推
聚合 Merge
Intersect Reorder
常量折叠
公共表达式复用
子查询改写
Lateral Join 化简
Empty Node 优化
Empty Union, Intersect, Except 裁剪
In 转 Semi Join 或者 Inner Join
http://mysql.taobao.org/monthly/2023/01/01/
https://mp.weixin.qq.com/s/-VNQRyZflHC6yTMbjL1XDA
TOPN Push down Outer Join
https://github.com/StarRocks/starrocks/pull/30128
聚合算子复用
比如对于下面的 SQL:
SELECT AVG(x), SUM(x) FROM table
我们可以让 AVG(x) 复用 SUM(x) 的计算结果,减少计算量
Primary Key 相关优化
冗余 Group By 消除
Sum 常量转 Count
常见的 CBO 优化
多阶段聚合优化
Join 左右表 Reorder
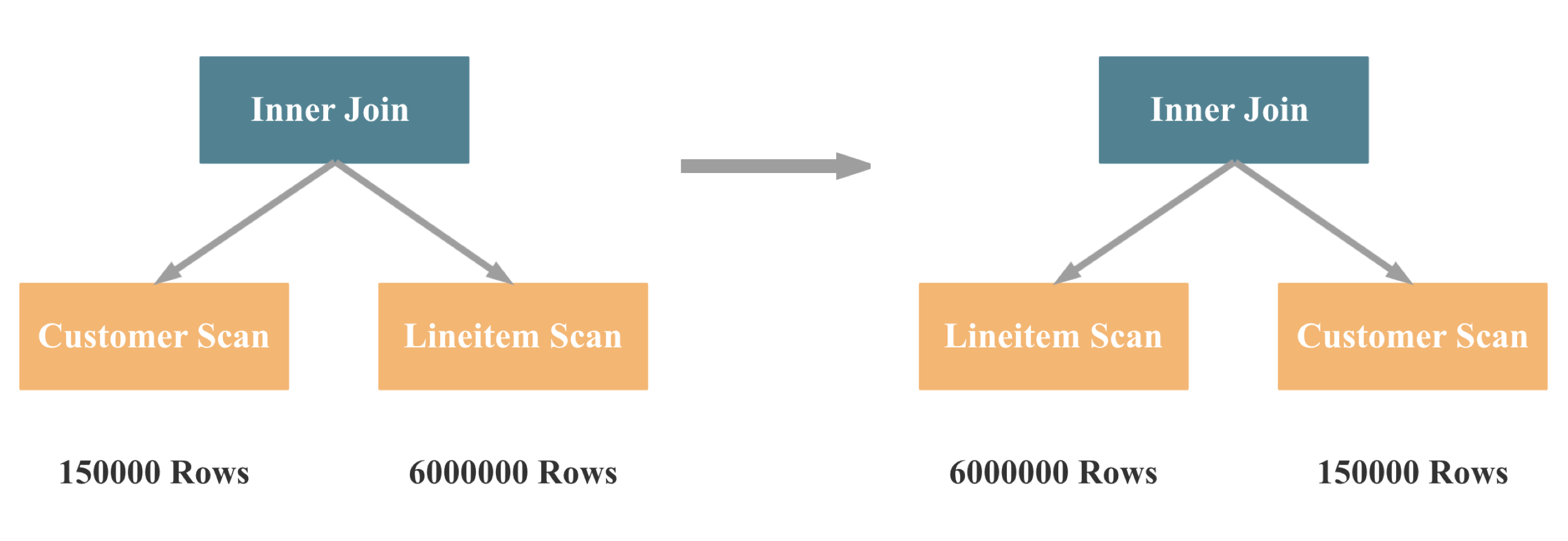
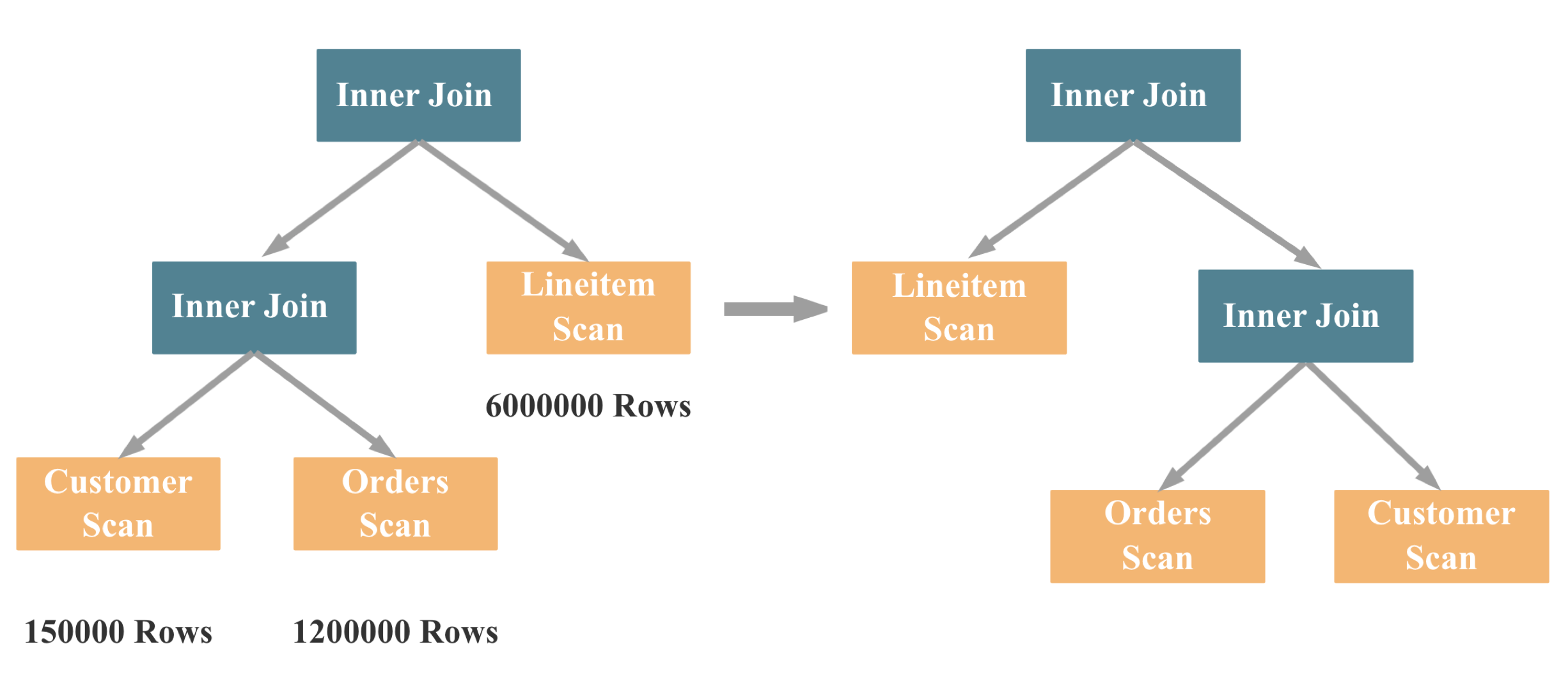
Join 多表 Reorder
Join 分布式执行选择
Shuffle Join
Broadcast Join
Bucket Shuffle Join
Colocate Join
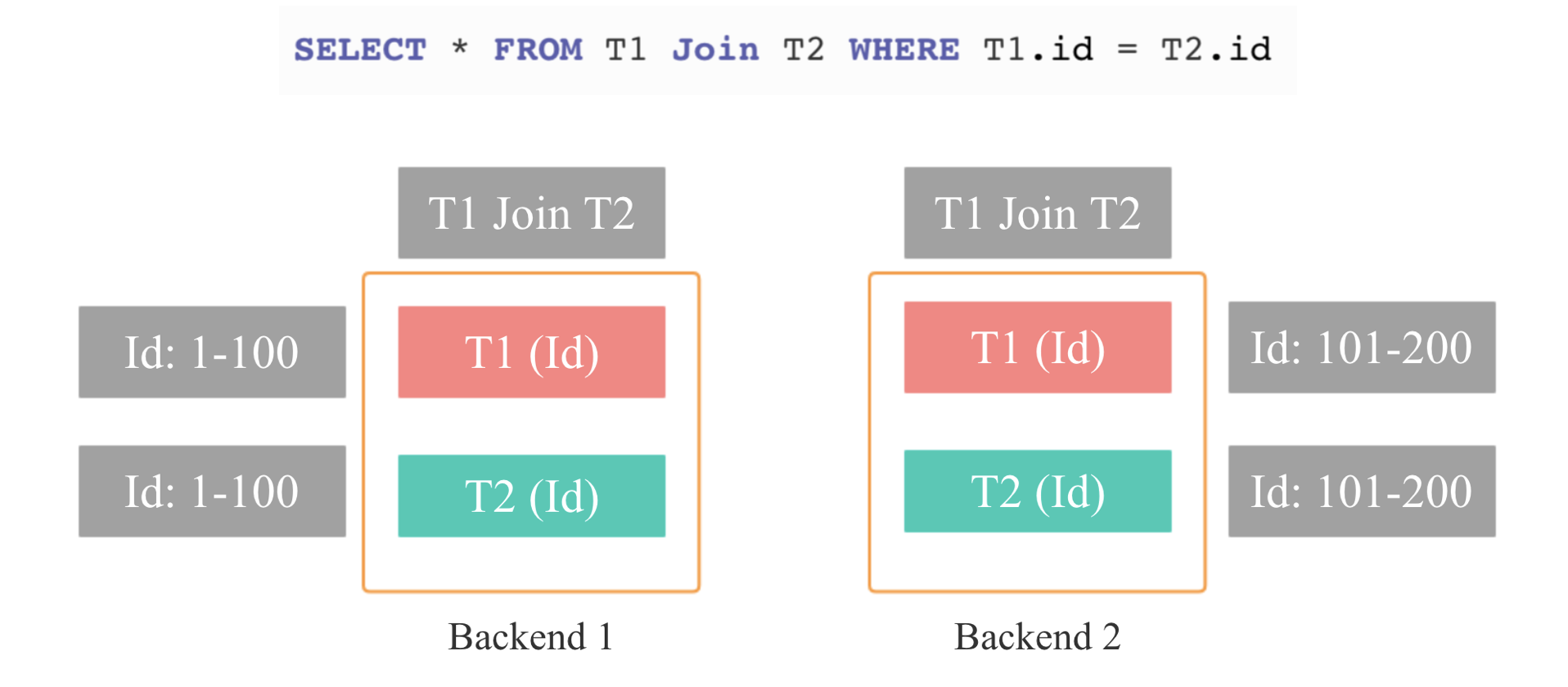
Replication Join
Join 和 Aggregate Runtime Colocate, 避免 Shuffle
CTE 复用
CTE 列裁剪
Agg 上拉
Agg 下推 Join
Agg 下推 GroupingSets
窗口下推 Group By
算子融合
物化视图选择与改写
利用基数信息进行优化
Join 消除
https://mp.weixin.qq.com/s/bwYNNBmMAWFgJbJeUAwGnQ
统计信息
统计信息的收集方式
统计信息的收集频率
统计信息 Cache
优化器本身耗时的优化点
- Multi-Stage Optimization
- 按需 Explore group
- Upper bounds Pruning
- Memorize
- Multi Join Reorder
- Top-Down + Bottom Up Property Enforce
- Support Physical Plan Rewrite After Cascades